设为首页
收藏本站
开启辅助访问
切换到窄版
快捷导航
登录
|
立即注册
门户
Portal
论坛
BBS
淘宝
腾讯
谷歌
雅虎
百度
搜狐
新浪
网易
京东
搜索
搜索
热搜:
活动
交友
discuz
本版
文章
帖子
用户
蓝色火焰
»
论坛
›
蓝色火焰
›
百度
›
百度基于 Doris 的应用实践
返回列表
百度基于 Doris 的应用实践
2
回复
330
查看
[复制链接]
微信扫一扫 分享朋友圈
奥海
当前离线
积分
26
奥海
1
主题
15
帖子
26
积分
新手上路
新手上路, 积分 26, 距离下一级还需 24 积分
新手上路, 积分 26, 距离下一级还需 24 积分
积分
26
发消息
发表于 2022-12-13 17:12:36
|
显示全部楼层
|
阅读模式
导读:
大家好,今天和大家分享一下 Apache Doris 以及百度基于 Apache Doris 研发的商业化产品 Palo 的原理和应用实践,首先做一个简单的自我介绍,我叫杨政国,是 Apache Doris 的 PMC,同时也是百度资深研发工程师。
今天的分享主要分以下几个部分,首先介绍一下 Doris 的发展历程,之后会介绍 Doris适用场景,之后会比较详细的介绍 Doris 核心的产品特性,最后会介绍一下 Doris未来的发展的趋势和在规划中的一些新的 Feature。
全文目录:
Doris 的发展的历程
Doris 的应用场景
Doris 的核心特性
Doris的未来展望
Palo
<hr/>分享嘉宾|杨政国 百度 资深研发工程师
编辑整理|张建闯 BOSS直聘
出品社区|DataFun
<hr/>
01/Doris 的发展的历程
Apache Doris 是百度自研并且开源的一个 OLAP 数据库,它在查询性能和易用性上都做的非常好,能够完全支持标准 SQL,并且通过 MySQL 协议的方式兼容绝大部分的 BI 工具,能够在海量数据上进行实时分析,在秒级甚至毫秒级就可以返回查询结果,能够有效支撑多维分析、实时交互分析等多种场景。
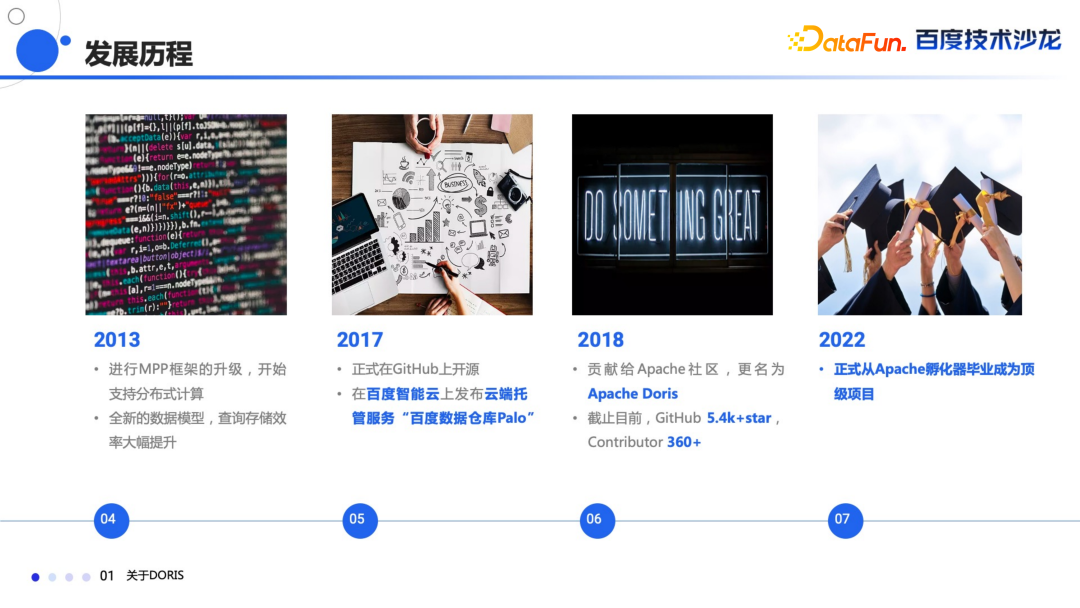
2008 年正式上线,服务于百度的凤巢,上线之后数据的更新频率从原来的天级变成了分钟级;
2009 年内部进行了通用化的改造,开始承接公司内部其他的报表需求;
2012 年承接了百度内部几乎所有的报表业务;
2013 年进行全面 MPP 框架升级,开始支持分布式计算,对于底层的数据模型做了大规模的改进,查询和存储效率都有极大的提升;
2017 年决定把 Doris 在 GitHub 上进行开源;
2018 年贡献给 Apache 社区,并正式更名为 Apache Doris,截至目前在 GitHub 有 5.4k 多的 Star,Contributor 数量超过了 360;
2022年 6 月份正式从 Apache 孵化器毕业,成为 Apache 的顶级项目。
--
02/Doris 的应用场景
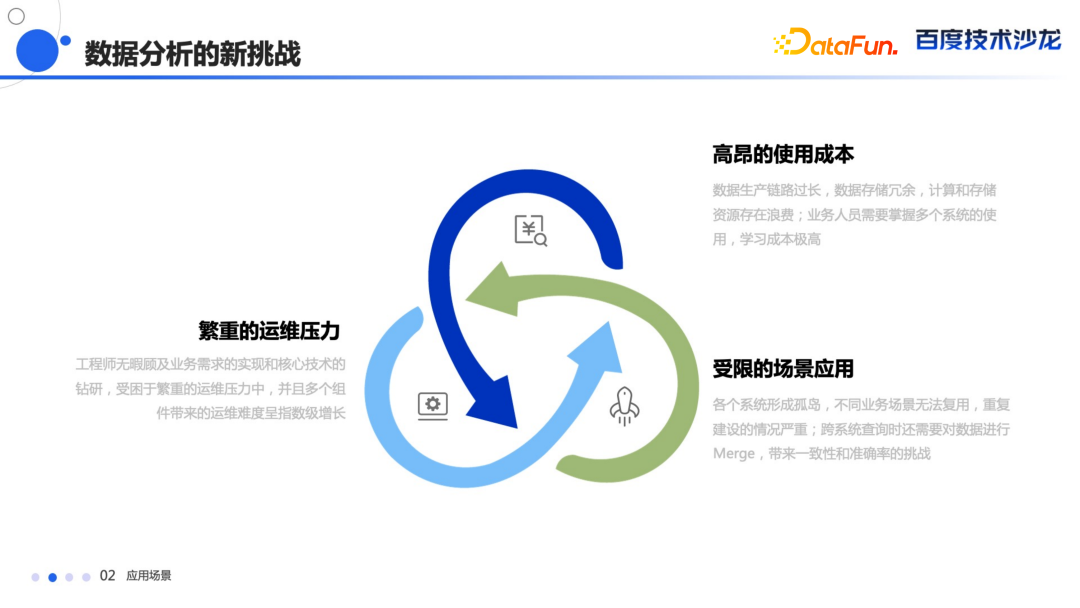
随着业务的发展,大家会有下面一些
痛点
:
查询效率低下,需要一个快速查询响应的工具。
分析时效性提高,随着业务的发展,T+1 的分析已经不能够满足业务要求。
需要更灵活的方式去应对业务趋势和系统建设滞后的矛盾,以及交付周期长的问题。
随着业务分析人员的增多,需要更低门槛的分析工具,来满足全民数据探索的需求。
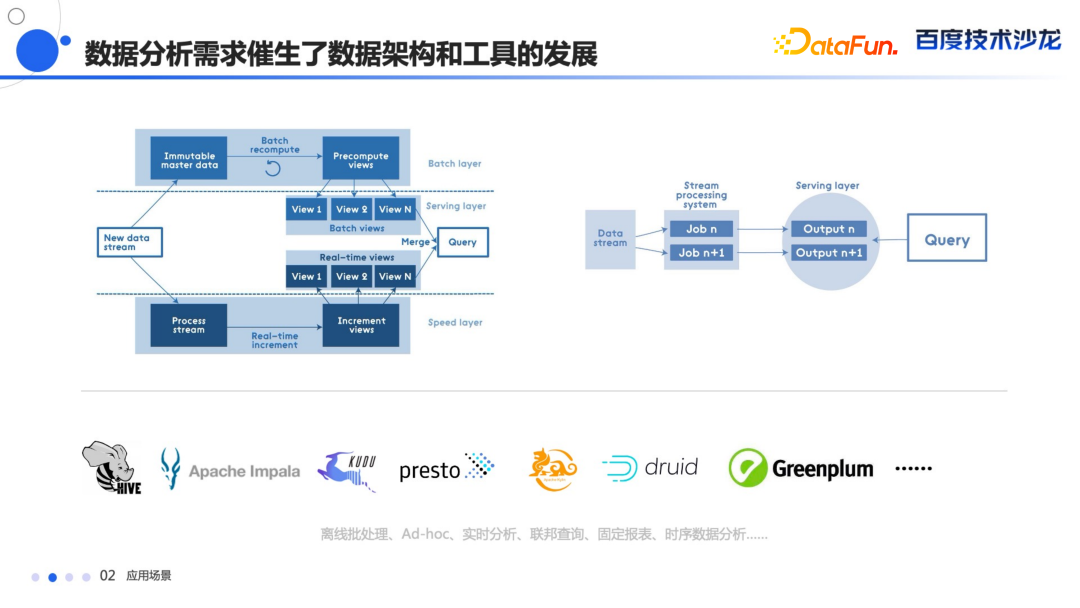
随着技术的演进催生了很多的数据架构和工具,比如像 Hive,Impala 等,它们分别解决了离线批处理和实时分析、联邦查询、固定报表等各种场景的需求。
随着这些工具的发展,在公司内部就出现了数据孤岛的情况,这个又会催生一个新的问题。
每一个工具都有自己的使用场景,导致各个系统的数据形成孤岛,没办法通过一个工具去统一整个数据的查询。数据生产的过程比较长,数据冗余比较严重,计算和存储资源存在浪费。
随着组件的增多,运维压力会呈指数级增长。
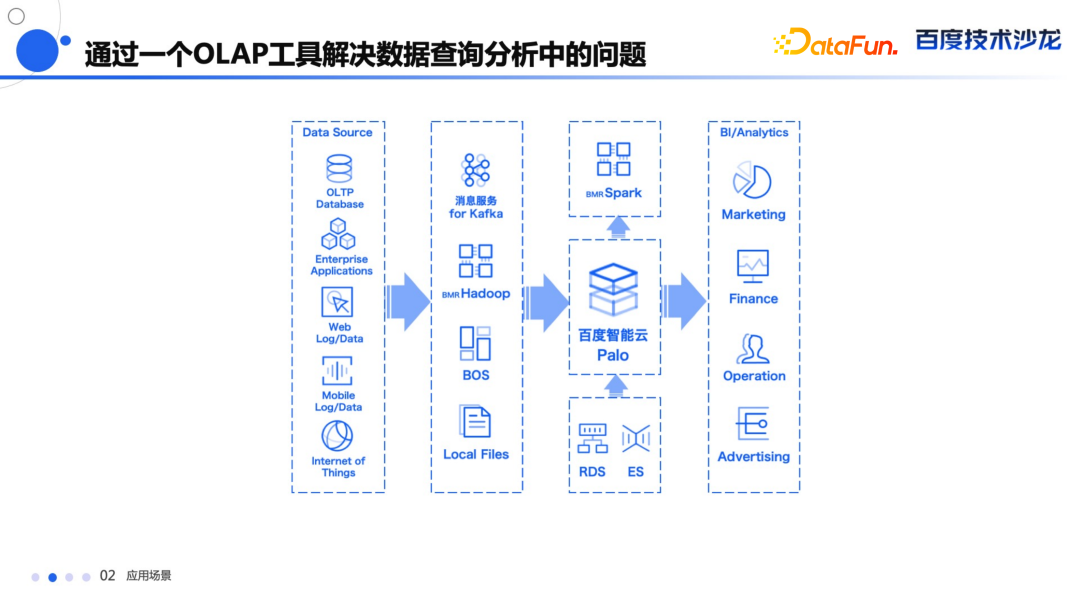
Doris
就是在这个场景中诞生的一个工具。
它能够提供以下能力:
海量数据上面提供亚秒级查询延迟响应。
支持流式数据的导入,完成实时的业务洞察。
统一大数据平台平台架构和数据流。
还能通过跨多数据源的联邦查询,支持像 ODBC,Hive,Iceberg,Hudi,ES等多种数据源。
能通过多种 Connector 和 Flink、Spark 这些数据分析工具有非常良好的交互,满足业务人员多元化查询需求。
通过 MySQL 协议能够方便地和其他的 BI 工具进行无缝的对接,提供对海量数据的自助探查和多维度分析的能力。
Doris
实现这些功能主要有下面这些
核心优势:
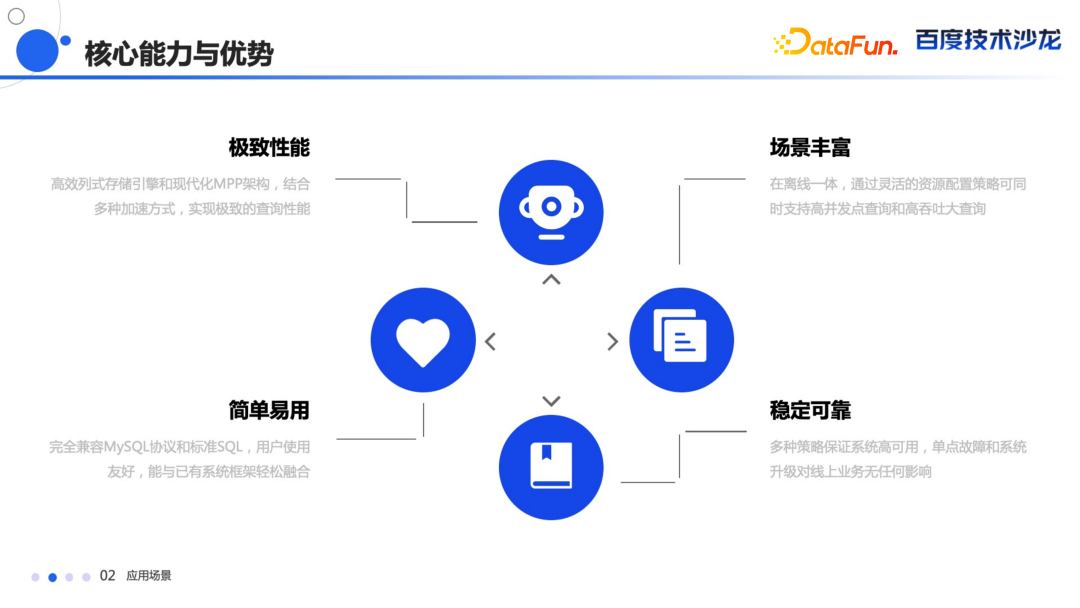
通过内部的各种优化手段,提供极致的性能。
通过灵活的种资源配置能够同时支持高并发和高吞吐的大查询,支持非常丰富的查询场景。
兼容 MySQL 协议,支持标准 SQL,非常简单易用,能够与现有系统非常好的融合。
内部提供多种高可用的策略的保证,像单点故障和系统升级等对线上业务基本无感。
--
03/Doris 的核心特性
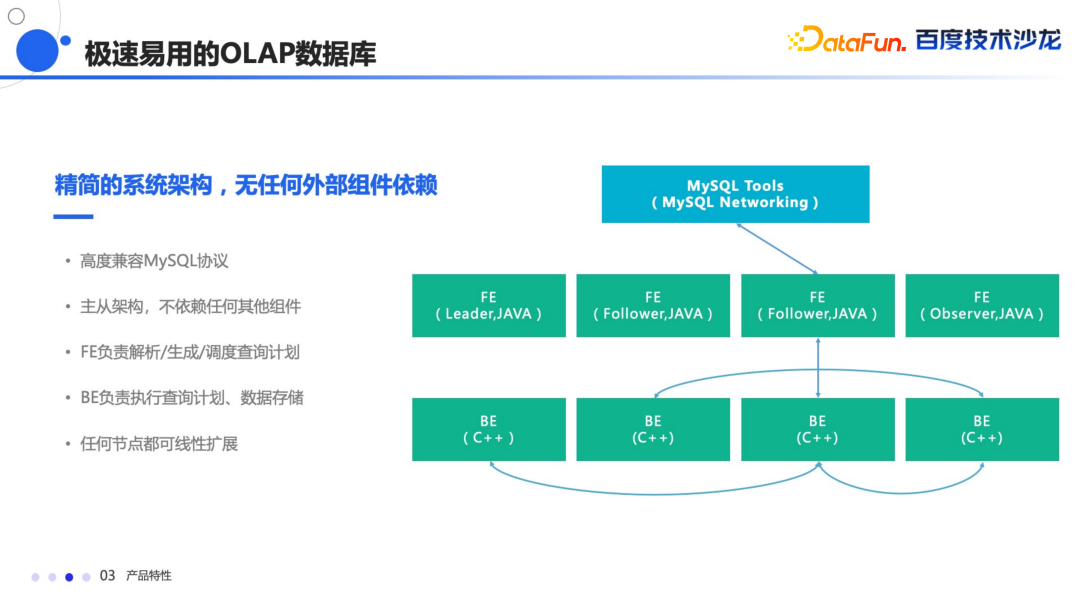
Doris 是一个典型的主从的架构,高度兼容 MySQL 协议,主要有两种节点FE 和 BE,FE 主要负责查询计划的解析生成以及调度,BE 主要负责查询计划的执行和数据存储,所有节点都可以根据业务的需求进行线性的扩展。
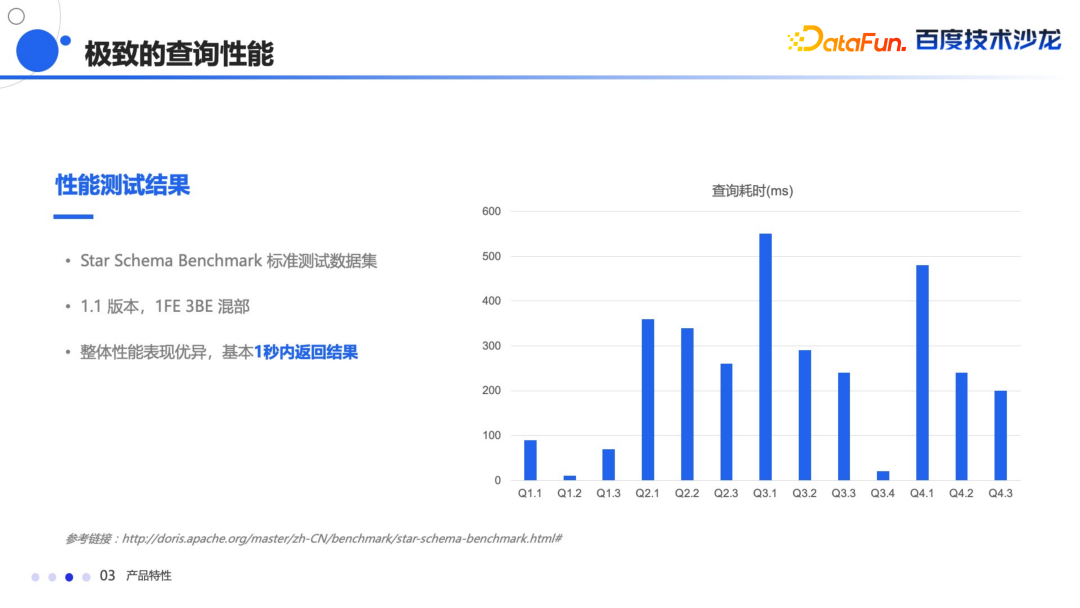
Doris 在 SSB 标准测试集上有非常好的查询效果。
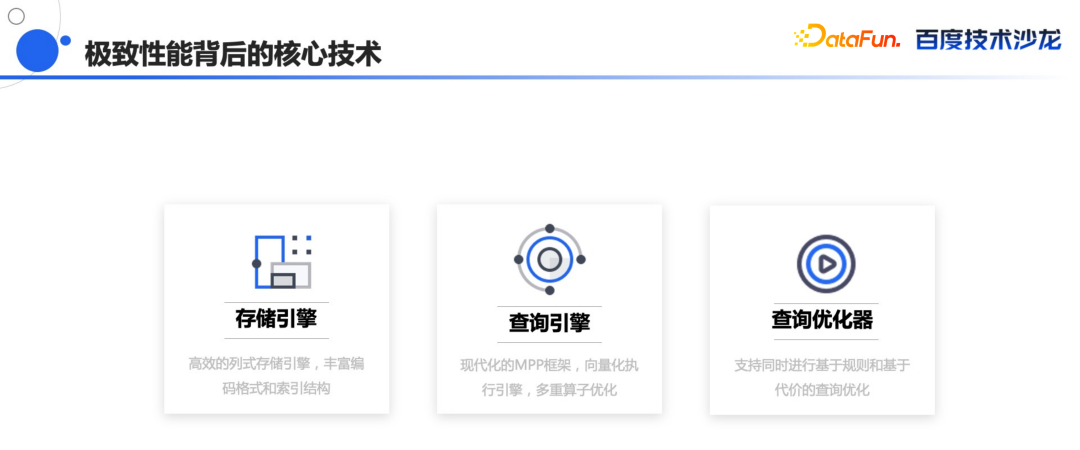
Doris 的这些极致的查询性能,主要由存储引擎,查询引擎,还有优化器这三个部分来提供。
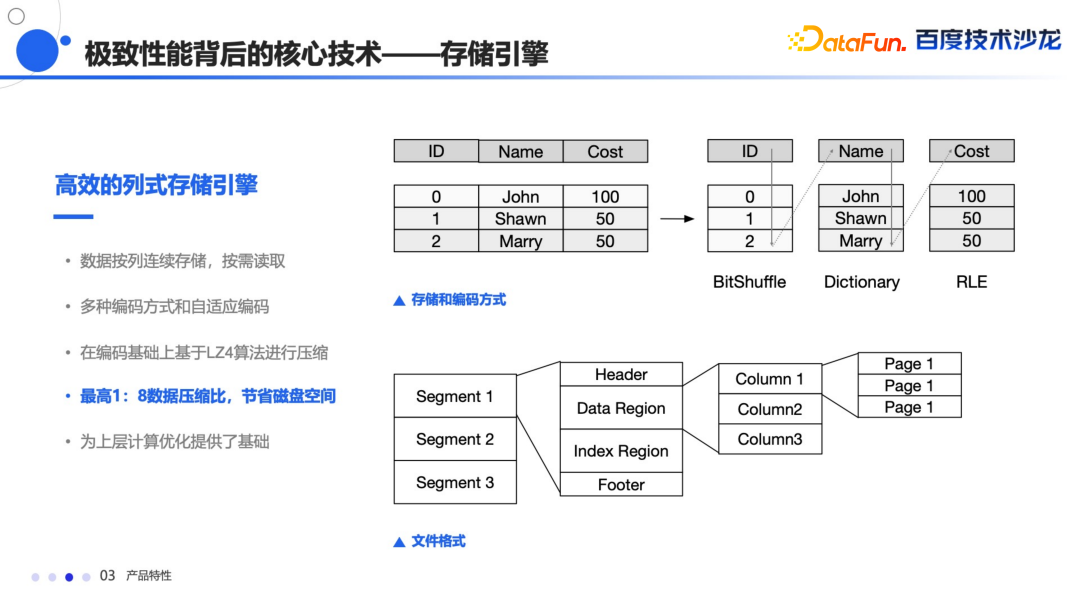
存储引擎是高效的列式存储,能够按需读取,同时支持多种编码方式,另外在编码的基础上还进行了压缩,最高能够达到 1:8 的压缩比,从而大幅节省磁盘空间。
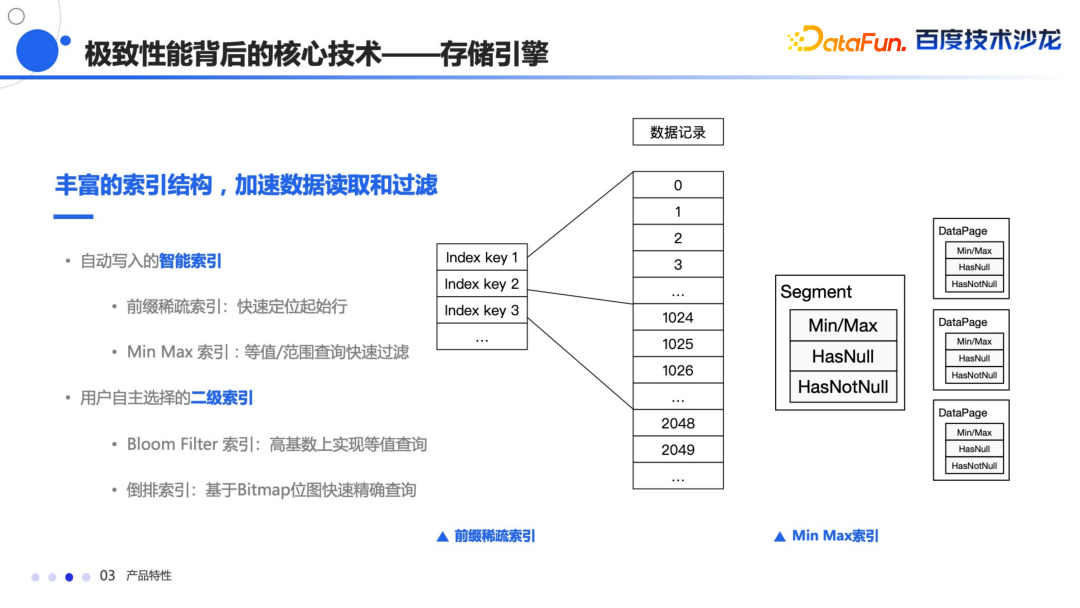
另外支持非常丰富的索引结构,除了在自动写入的时候所带的稀疏索引,还有 Min Max 索引以外,还支持用户自己去定义 Bloom Filter 和 Bitmap 索引等等。
Bloom Filter 索引主要提高高基数上的等值查询的性能
Bitmap 索引能够快速的进行精确的查询定位
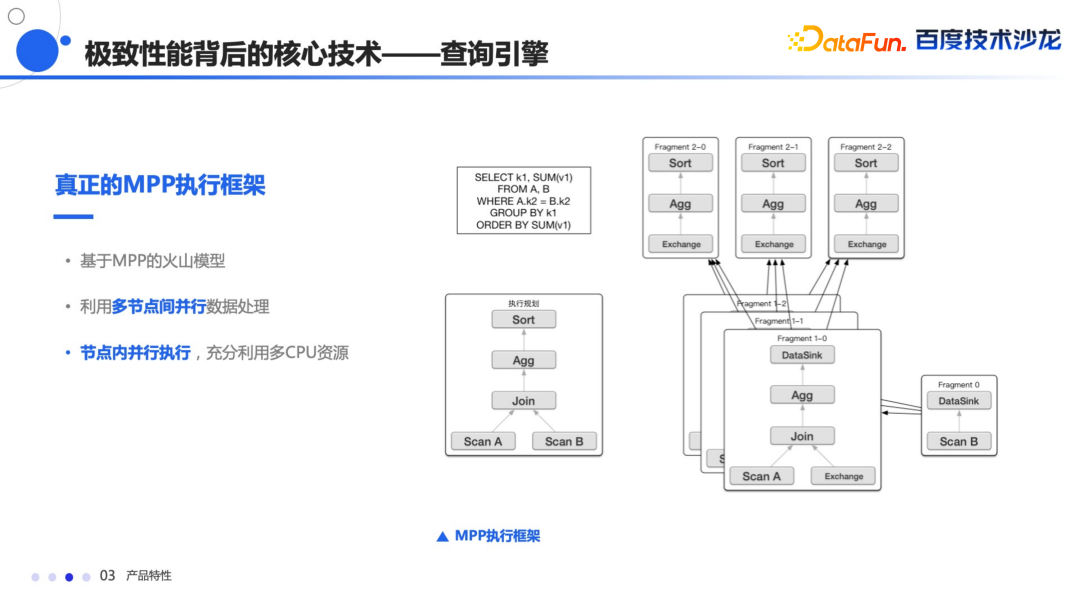
本身是基于 MPP 的火山模型的执行框架,所有的节点都是自上而下的调用get_next,数据会从最底层的 Scan 节点逐层返回,能够利用多节点并行的处理数据,充分利用机器资源,同时节点内部也是并行执行的,能够充分利用 CPU 的计算资源,以图中 Select 语句为例,他的执行计划因为有两个表所以会有两个 Scan 节点,然后上面会有 Join,Join 之后会把结果发送到聚合节点,最后通过排序再返回给客户端,整个规划的都是可以并行执行的。
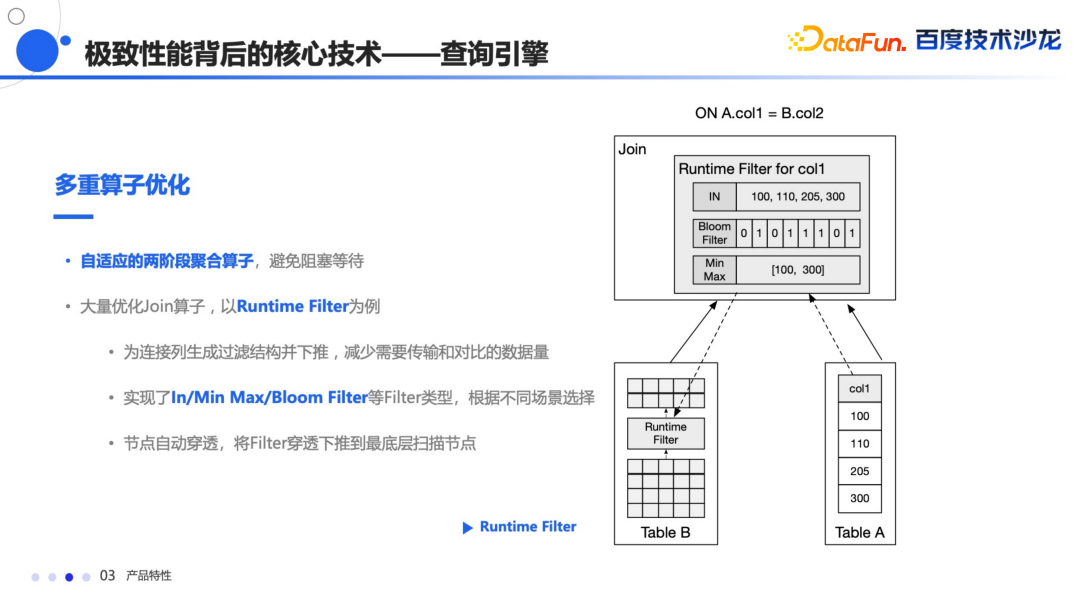
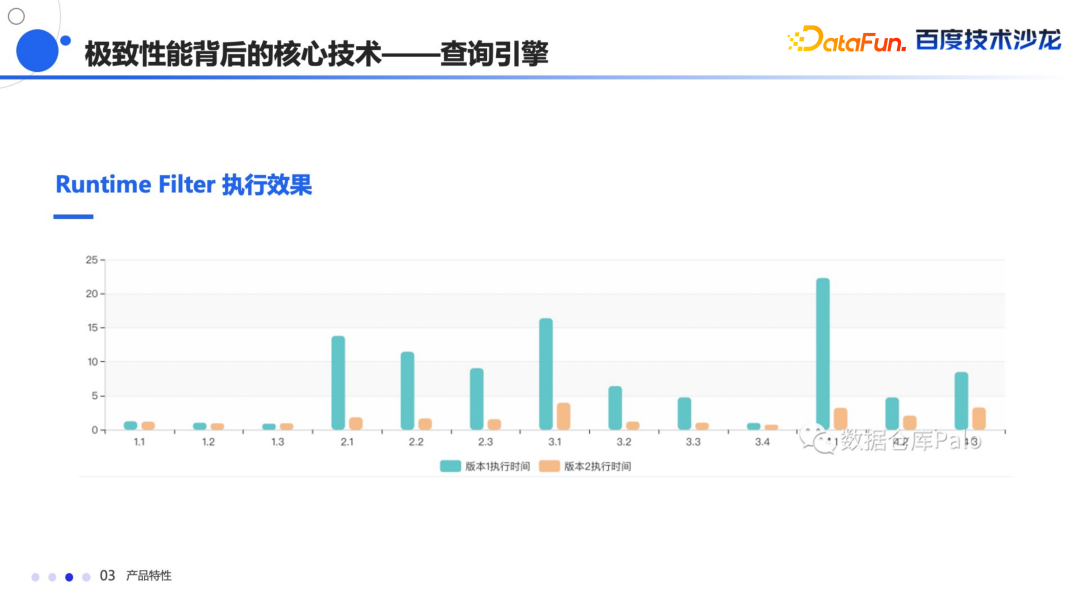
除了执行框架以外,还做了多重的算子优化,今天主要介绍一下 Runtime Filter,主要用在 Join 时左右表的数据量差别较大的场景,他会将小表的结果转换成过滤结构,推送给大表,在大表的存储层进行过滤,从而减少数据传输和对比的数量,目前实现了 In、Min-Max、Bloom Filter 等多种 Filter 数据类型,能够根据不同场景自动穿透到最底层的扫描节点,从而大幅提升查询效率。
这是在 TPC-DS 上面的测试,开启 Feature 之后可以看到性能提升非常明显。
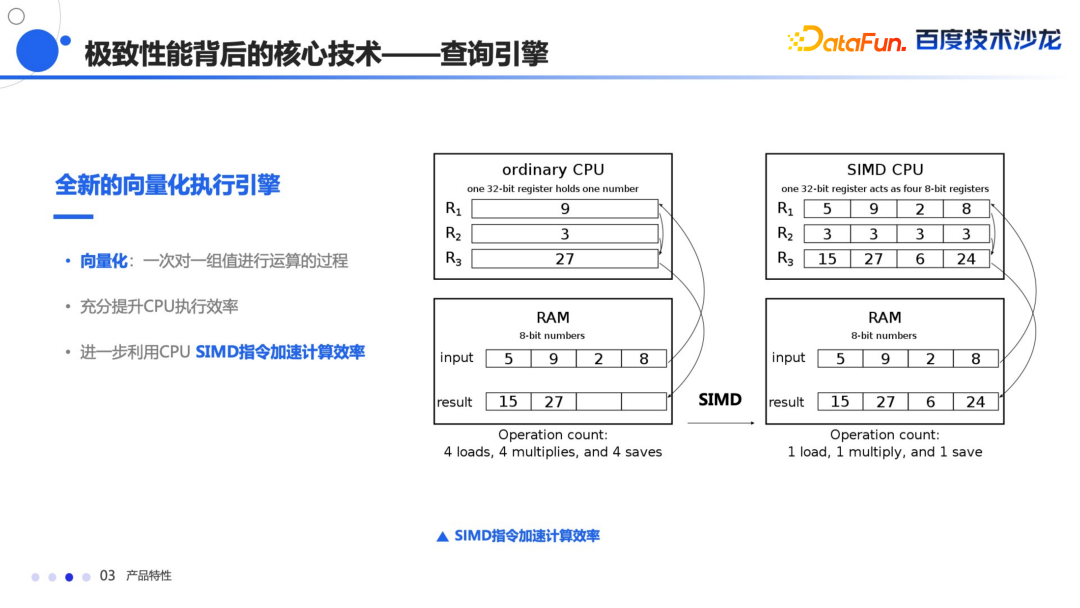
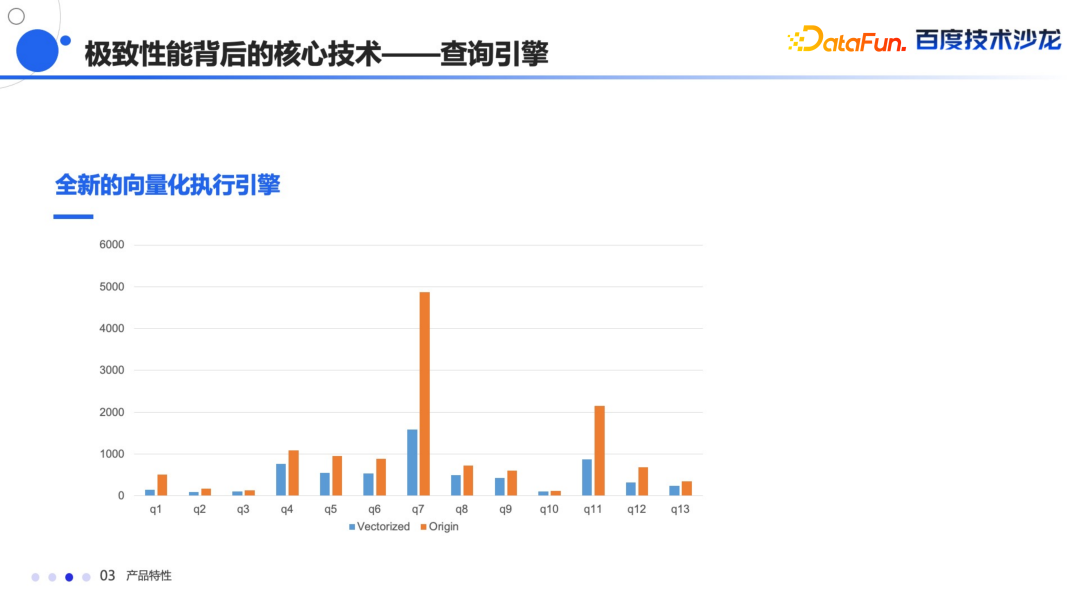
除了上面讲的传统优化以外,还实现了向量化的执行引擎,通过向量化的方式,减少了 CPU 对虚函数的调用和分支的判断,然后通过列存结构能够使代码更好的去适用于编译器的优化,能够增强数据和指令在 CPU 上的亲和度,更进一步利用 CPU 的 SIMD 指令加速计算。
这个效果非常的明显,尤其是在一些较大的查询上,数据量越大,它的效果会越明显。
除了存储和计算上的优化,在查询优化器上也做了大量的工作。
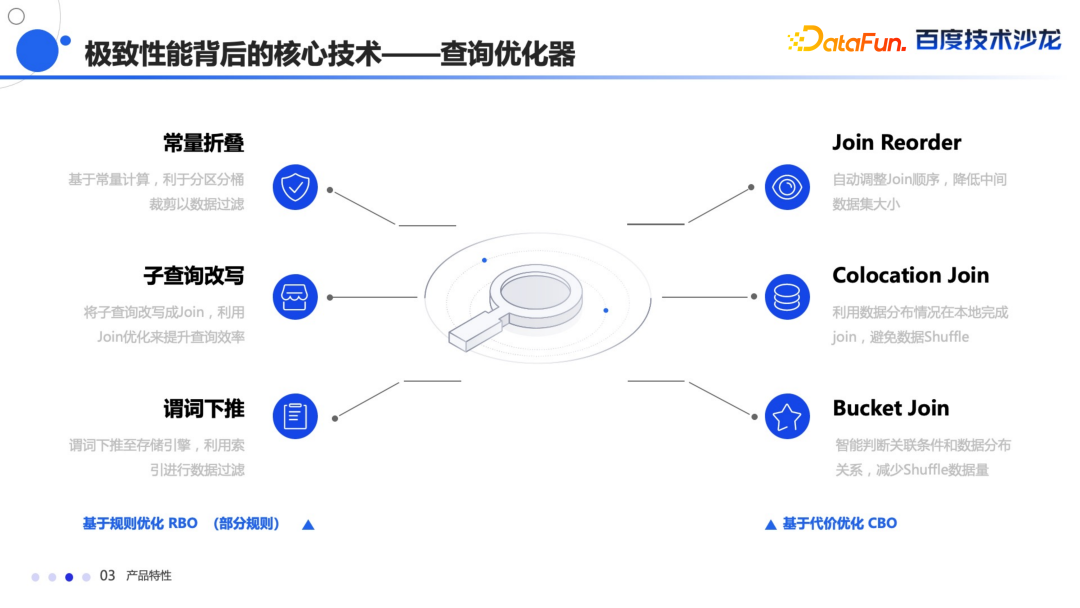
基于规则的优化:
常量折叠
子查询的改写
还有谓词下推
基于代价的优化:
Join Reorder:自动根据数据的分布和大小自动调整 Join 顺序。
Colocation Join:在数据存储的时候,会根据规则,将数据按照一定顺序规则分布到相同的节点上,在 Join 的时候能够完成本地 Join,避免数据 Shuffle,从而大幅提升查询性能。
Bucket Join:这是 Colocation Join 的升级版本,它会自动判断关联条件中的数据分布关系,如果符合要求,会自动进行 Colocation Join,从而减少数据的 Shuffle。
--
04/Doris的未来展望
在未来我们会做以下几个事情:
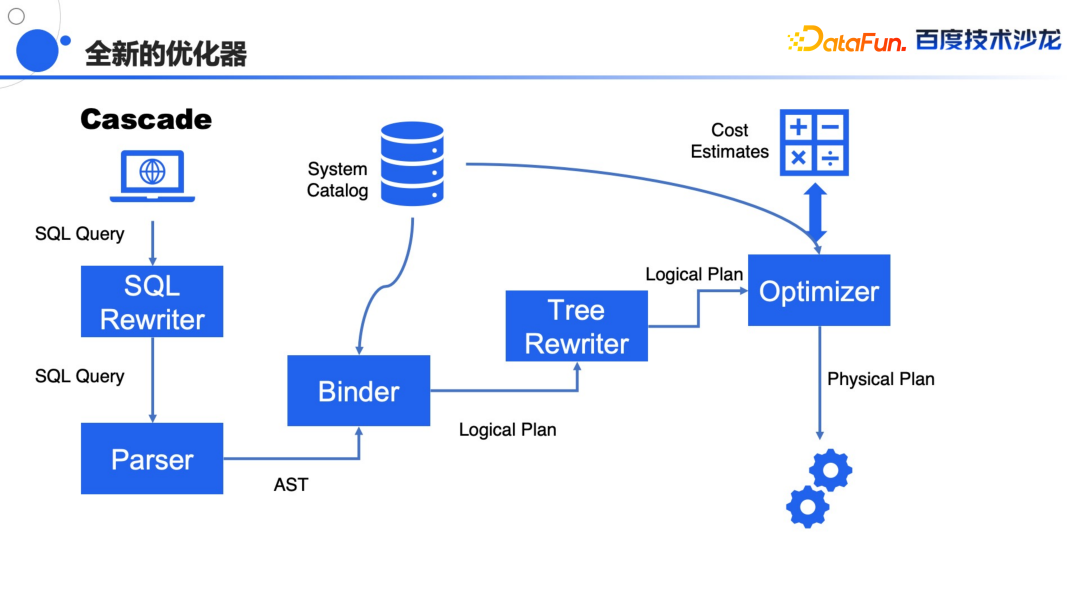
首先就是实现一个全新的一个优化器
,目前的优化器主要是基于规则的优化器,它对于数据的变化没有那么敏感,在未来要实现 Cascade 这样更加优秀和普适的优化器,能够支持更多语法,对数据变化更加敏感,能够实现更完善的全局最优的优化方案,这个现在已经在做了,大家可以期待一下。
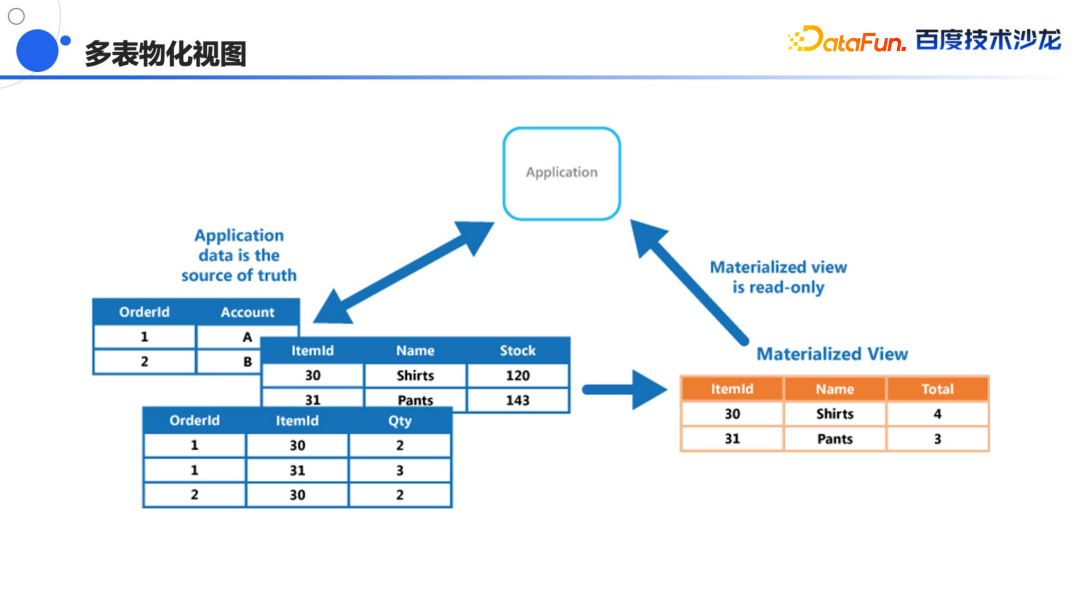
其次就是多表物化视图
,目前已经支持了物化的能力,但是这个物化是单表,通过物化视图可以加速单表的查询,可以在基表上建一些上卷的物化视图,对某些列进行聚合,优化器会自动选择最优的视图进行查询,多表物化视图是在对表的数据变化不敏感,但查询比较复杂又有一定规律性的情况下,可以将这个数据建到一个物化视图表里面去,这张表会随着用户数据的更新的自动更新,或者通过不同的策略进行更新,允许部分数据的延迟,将查询结果存到一张表里,以后直接查询这张表,就可以节省大量的计算资源。
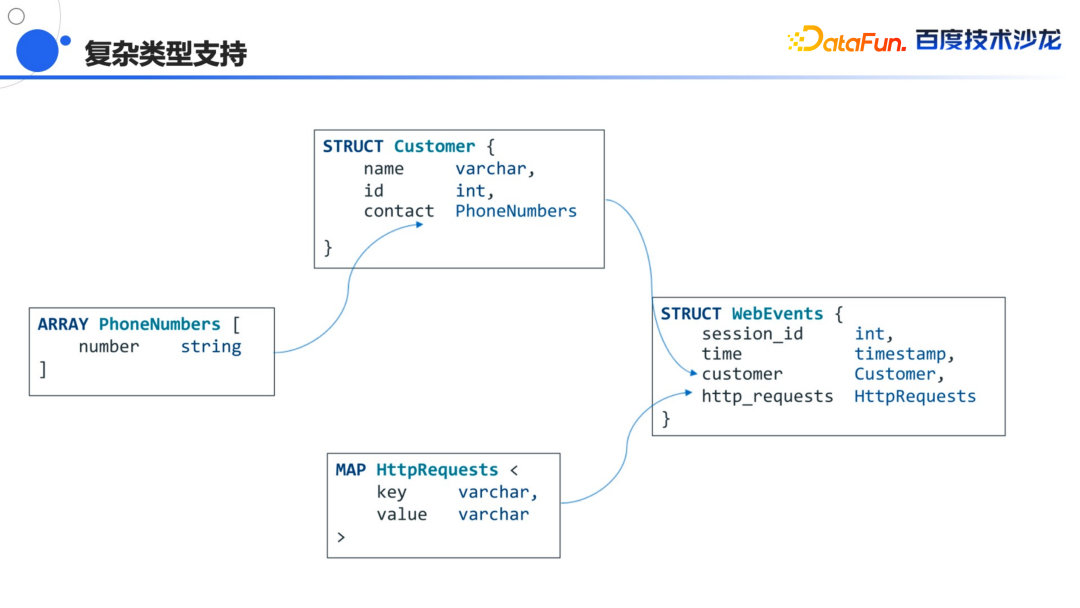
另外一个是在复杂类型上面,Doris 之前是不支持复杂类型的,比如说 Array类型就是一个相同类型的有序的元组组成的一个集合,还有 Struct,它就是一堆的 K-V 对,Key 和 Value 可以是各种类型,Map 是相对比较集中的类型,Key 和 Value 都是同类型的,在一些大数据生态里面像 Spark、Hive 都支持复杂类型,那在这种生态下通过外表查询的时候,可能会导致一些数据的不兼容,导入到 Doris 也会有些问题,因此
我们在这方面也会做更多的工作。
--
05/Palo
Palo 是一个完全基于 Doris 做的数仓的产品,在 Palo 上有很多优势:
能够充分利用云平台的优势,能够按需去取用海量的资源,可以更加可控的进行资源管理。
即将上线基于对象存储的冷热分离的架构,降低数据成本,也能够结合缓存策略对冷数据进行快速查询。
提供更丰富的云上的管控和监测工具,能够快速的扩容缩容,变配啊,程序启停,监控报警功能,同时提供一些企业级的生态组件,帮助用户去自助的取数分析。
另外也支持多种灵活的部署方式,刚刚提到的是公有云的形式,我们也支持私有云的部署和本地的私有化部署。
Palo 其实是从我们内部复杂的业务场景中打磨出来的,百度内部有 200 多的业务线长期在使用,使用的时间长达 10 年以上,包括像百度凤巢、手百、大商业、小度等多个核心部门都在使用,集群规模近千个,同时也有大量的对外输出的客户的成功经验,付费的用户近百家,能够覆盖到互联网金融、电商、政务、交通、制造、资讯媒体等多个行业,我们的产品能够稳定支持各个业务的使用,深度的理解业务的情况,也有非常的丰富的运维经验,而且积累了大量的客户的成功经验,同时基于这个非常繁荣的开源生态,目前我们的开源社区也非常活跃,整个开源用户的使用群体提供了大量的一些 Case 和使用场景,能够使我们的产品的更加的稳定和完善。
欢迎大家的登录百度云的官网,体验这个产品,我们在云上有非常完善的管控平台,包括交互式数据探索的一系列的工具给大家使用。
今天的分享就到这里,谢谢大家。
<hr/>
分享嘉宾
杨政国|百度 资深研发工程师
百度资深研发工程师, 百度 palo团队技术负责人。2014 年加入百度,长期从事大数据和机器学习方向研发,是Apache Doris 社区的PMC成员之一,Doris 社区的核心贡献者之一。
<hr/>
DataFun新媒体矩阵
<hr/>
关于DataFun
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。
回复
使用道具
举报
新海正
当前离线
积分
21
新海正
0
主题
13
帖子
21
积分
新手上路
新手上路, 积分 21, 距离下一级还需 29 积分
新手上路, 积分 21, 距离下一级还需 29 积分
积分
21
发消息
发表于 2025-5-1 12:32:57
|
显示全部楼层
支持你哈...................................
回复
使用道具
举报
你最凶我最爱
当前离线
积分
30
你最凶我最爱
3
主题
14
帖子
30
积分
新手上路
新手上路, 积分 30, 距离下一级还需 20 积分
新手上路, 积分 30, 距离下一级还需 20 积分
积分
30
发消息
发表于 2025-5-27 01:03:38
|
显示全部楼层
小白一个 顶一下
回复
使用道具
举报
叨叨魏
当前离线
积分
20
叨叨魏
0
主题
13
帖子
20
积分
新手上路
新手上路, 积分 20, 距离下一级还需 30 积分
新手上路, 积分 20, 距离下一级还需 30 积分
积分
20
发消息
发表于 2025-12-16 10:20:07
|
显示全部楼层
锄禾日当午,发帖真辛苦。谁知坛中餐,帖帖皆辛苦!
回复
使用道具
举报
越长越好
当前离线
积分
34
越长越好
4
主题
17
帖子
34
积分
新手上路
新手上路, 积分 34, 距离下一级还需 16 积分
新手上路, 积分 34, 距离下一级还需 16 积分
积分
34
发消息
发表于 2025-12-19 00:10:15
|
显示全部楼层
顶起出售广告位
回复
使用道具
举报
水公子
当前离线
积分
37
水公子
4
主题
20
帖子
37
积分
新手上路
新手上路, 积分 37, 距离下一级还需 13 积分
新手上路, 积分 37, 距离下一级还需 13 积分
积分
37
发消息
发表于 2026-1-18 00:23:14
|
显示全部楼层
围观 围观 沙发在哪里!!!
回复
使用道具
举报
韩小咪
当前离线
积分
33
韩小咪
3
主题
16
帖子
33
积分
新手上路
新手上路, 积分 33, 距离下一级还需 17 积分
新手上路, 积分 33, 距离下一级还需 17 积分
积分
33
发消息
发表于 2026-1-25 16:44:28
|
显示全部楼层
介是神马?!!
回复
使用道具
举报
背向我煮面
当前离线
积分
26
背向我煮面
1
主题
14
帖子
26
积分
新手上路
新手上路, 积分 26, 距离下一级还需 24 积分
新手上路, 积分 26, 距离下一级还需 24 积分
积分
26
发消息
发表于 2026-1-26 22:36:24
|
显示全部楼层
LZ帖子不给力,勉强给回复下吧
回复
使用道具
举报
胡为民
当前离线
积分
15
胡为民
1
主题
8
帖子
15
积分
新手上路
新手上路, 积分 15, 距离下一级还需 35 积分
新手上路, 积分 15, 距离下一级还需 35 积分
积分
15
发消息
发表于 2026-1-29 19:43:38
|
显示全部楼层
确实不错,顶先
回复
使用道具
举报
蓝色的红海
当前离线
积分
23
蓝色的红海
1
主题
14
帖子
23
积分
新手上路
新手上路, 积分 23, 距离下一级还需 27 积分
新手上路, 积分 23, 距离下一级还需 27 积分
积分
23
发消息
发表于 2026-1-31 12:21:12
|
显示全部楼层
支持楼主,用户楼主,楼主英明呀!!!
回复
使用道具
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
京东
雅虎
谷歌
快速回复
返回顶部
返回列表



 发表于 2022-12-13 17:12:36
发表于 2022-12-13 17:12:36