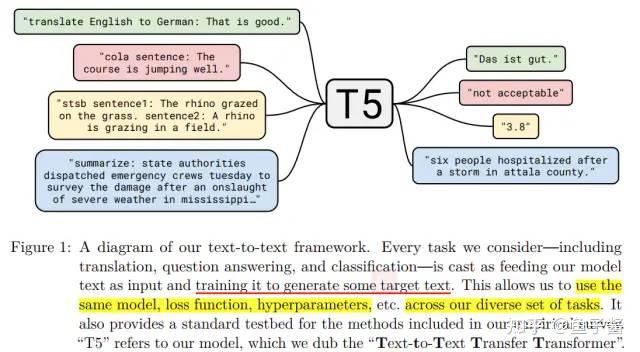
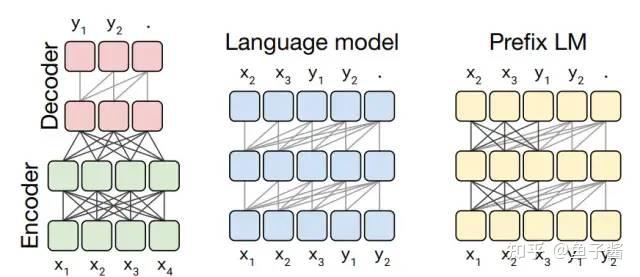
如图所示,T5(Text-to-Text Transfer Transformer)模型将翻译、分类、回归、摘要生成等任务都统一转成Text-to-Text任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数,在测试时也能使用相同的解码过程。
注意这里回归任务对应的浮点数会被转成字符串看待,从而可以token by token的预测出来。虽然感觉奇怪,but anyway, it works。
causal with prefix attention mask:输入序列的一部分前缀采用fully-visible attention mask,其余部分采用 causal attention mask。
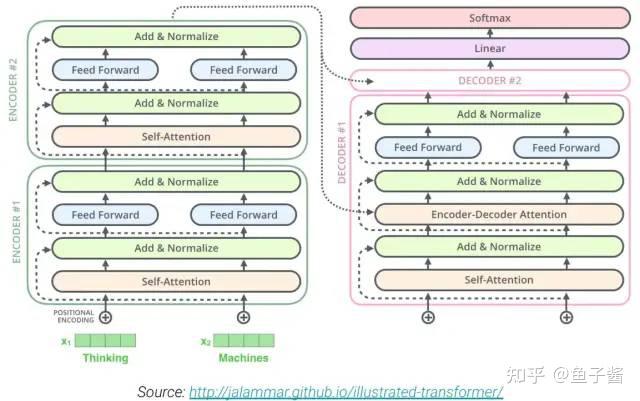
在最左侧的Encoder-Decoder结构中,Encoder部分采用fully-visible attention mask,而Decoder部分采用causal attention mask。
中间的Language model结构中,采用causal attention mask。
最右侧的Prefix LM结构中,采用causal with prefix attention mask。比如在翻译任务中,给定训练样本translate English to German: That is good. target: Das ist gut.,我们对translate English to German: That is good. target:采用fully-visible attention mask,对Das ist gut.采用causal attention mask。
总结
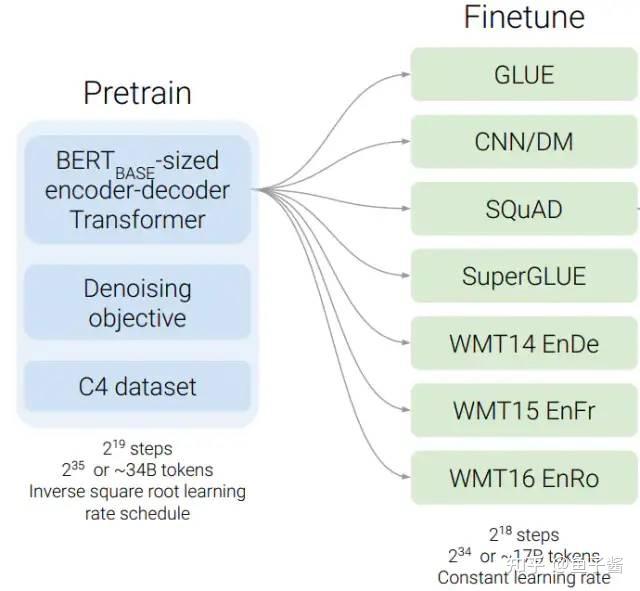
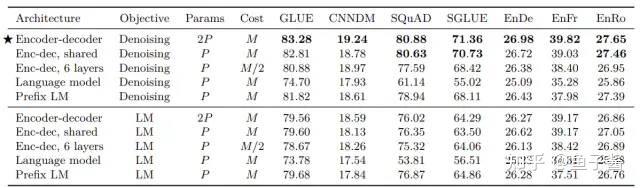
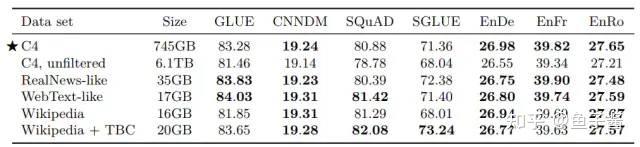
最后先来回顾下T5的特点: T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a different prefix to the input corresponding to each task, e.g., for a translation task: translate English to German: xxx...
个人感觉T5论文算是对当前NLP领域pre-train fine-tune主流模式下的各种训练技巧的一个总结和公平对比,分析各种训练技巧对模型性能提升的实际影响,从而采用合适的技巧预训练出一个好的模型。作者也说了,本文的目的不是提出一个新的方法,而是对NLP领域的一些技术支撑点提供一个较为全面的分析视角。
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Standford CS224N



 发表于 2022-12-12 13:16:11
发表于 2022-12-12 13:16:11