设为首页
收藏本站
开启辅助访问
切换到窄版
快捷导航
登录
|
立即注册
门户
Portal
论坛
BBS
淘宝
腾讯
谷歌
雅虎
百度
搜狐
新浪
网易
京东
搜索
搜索
热搜:
活动
交友
discuz
本版
文章
帖子
用户
蓝色火焰
»
论坛
›
蓝色火焰
›
谷歌
›
涨点神器!谷歌大脑提出:Dual PatchNorm
返回列表
涨点神器!谷歌大脑提出:Dual PatchNorm
2
回复
198
查看
[复制链接]
微信扫一扫 分享朋友圈
烽呈居士
当前离线
积分
35
烽呈居士
5
主题
16
帖子
35
积分
新手上路
新手上路, 积分 35, 距离下一级还需 15 积分
新手上路, 积分 35, 距离下一级还需 15 积分
积分
35
发消息
发表于 2023-3-4 07:35:46
|
显示全部楼层
|
阅读模式
一句话总结
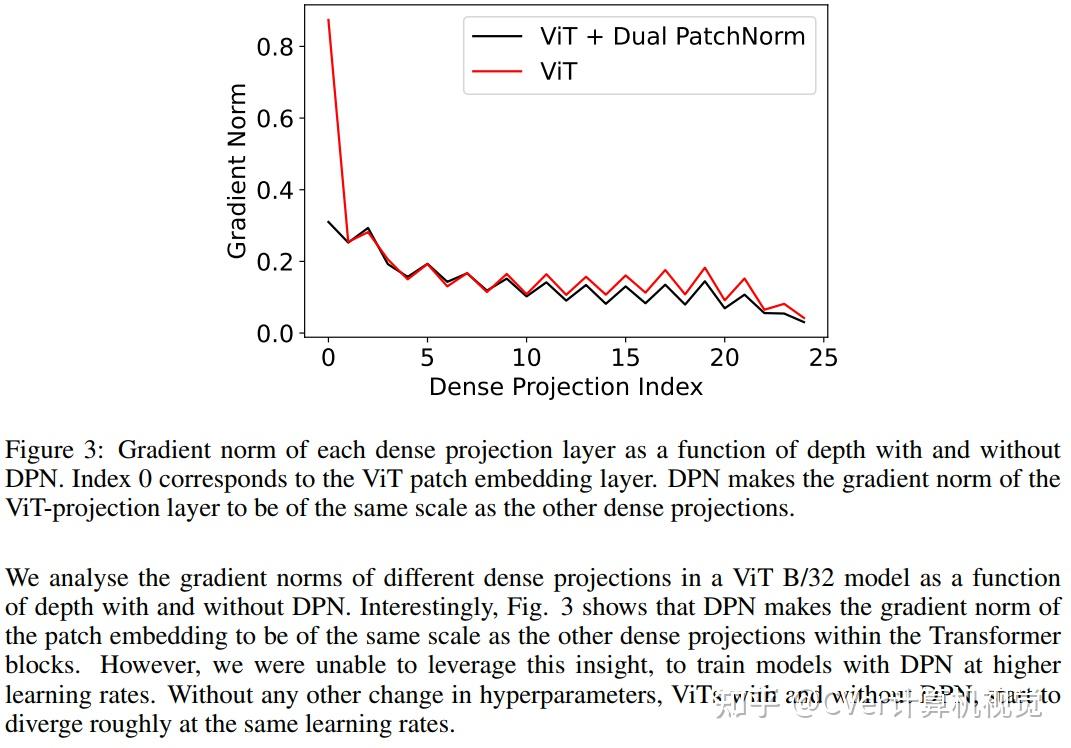
本文提出Dual PatchNorm:两个 Layer Normalization层(LayerNorm),即放置在Vision Transformers中的patch embedding层的之前和之后。
点击关注@CVer计算机视觉,第一时间看到最优质、最前沿的CV、AI工作~
点击进入—>
Transformer微信技术交流群
Dual PatchNorm
Dual PatchNorm
单位:谷歌大脑
论文:https://arxiv.org/abs/2302.01327
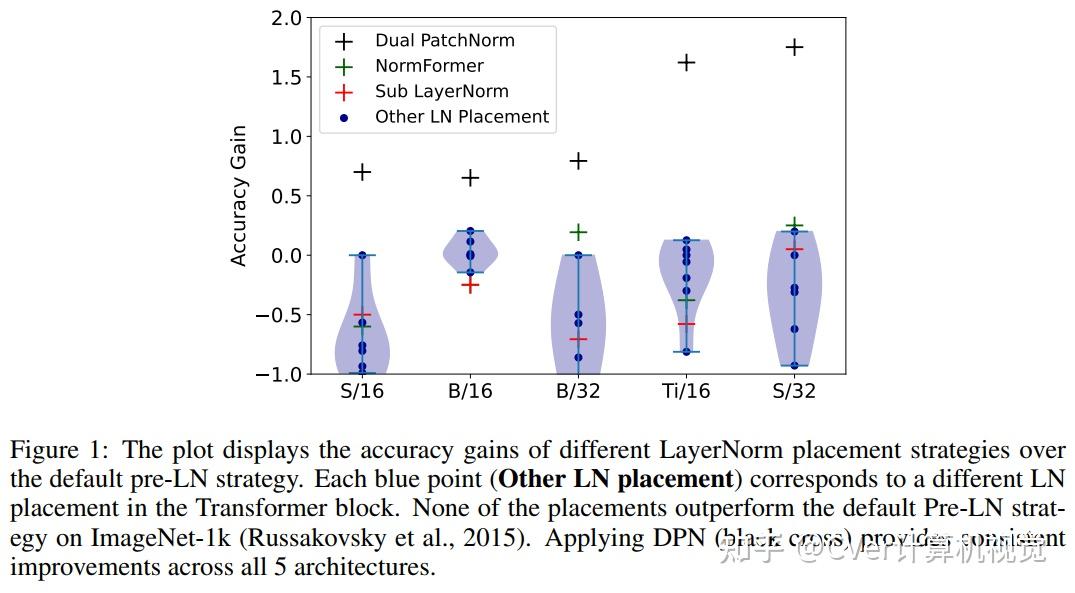
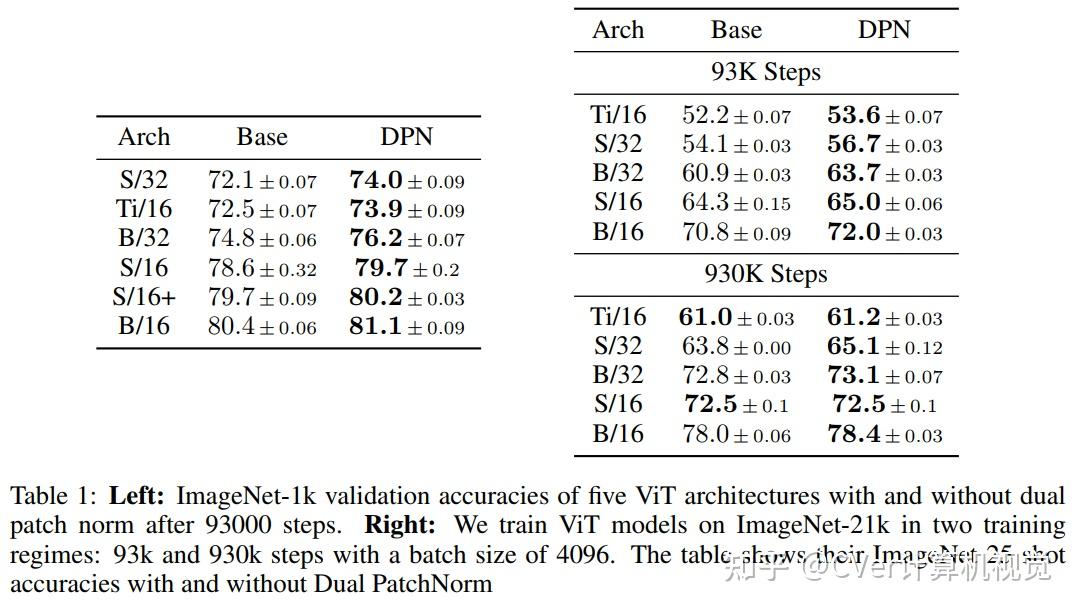
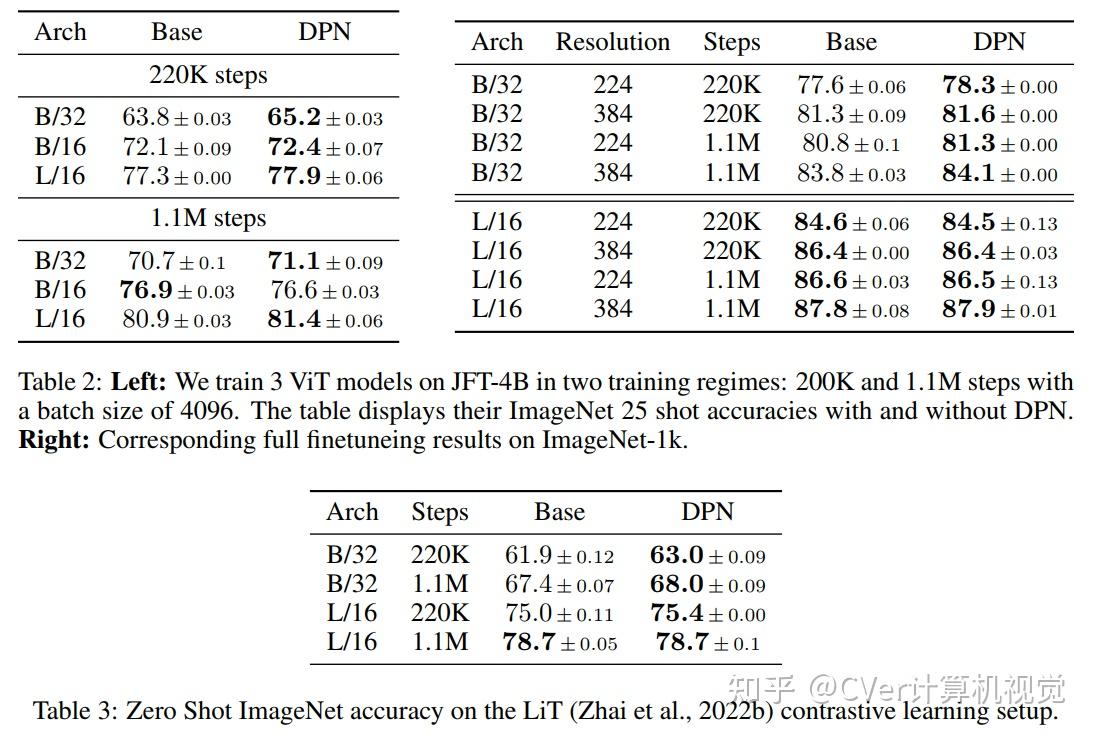
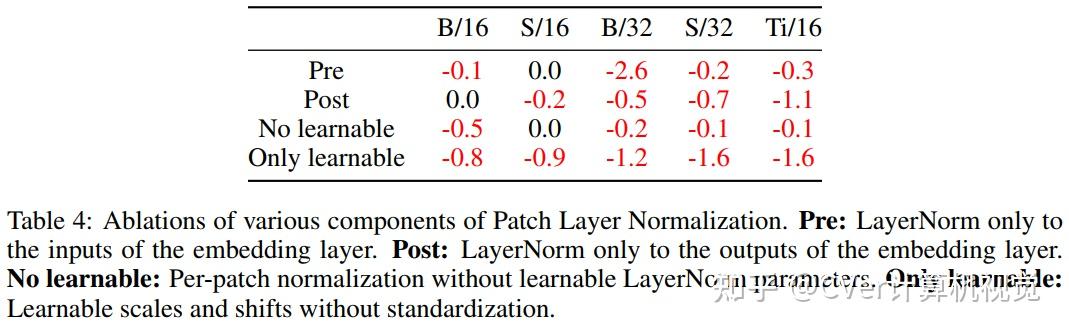
本文证明了Dual PatchNorm优于在Transformer块本身中对替代LayerNorm放置策略进行穷举搜索的结果。
实验结果
在我们的实验中,结合这种微不足道的修改,通常会比调谐良好的视觉Transformer提高精度,而且不会造成伤害。
点击进入—>
扩散模型微信技术交流群
CVer-扩散模型交流群
建了CVer-扩散模型交流群!想要进扩散模型交流群的同学,可以直接加微信号:
CVer222
。加的时候备注一下:
缺陷检测+学校/公司+昵称+知乎
,即可。然后就可以拉你进群了。
推荐阅读
ICLR 2023 高分论文!ImageNet上的3D生成
BLIP-2:使用冻结图像编码器和大型语言模型的语言-图像预训练
MedSegDiff-V2:基于Transformer和扩散模型的医学图像分割
涨点显著!FAIR提出CutLER:用于无监督目标检测和实例分割的切割和学习
超越YOLOv7、v8!YOLOv6 v3.0 正式发布
YOLOv8来了!YOLOv5官方团队出品!
ConvNeXt V2来了!使用MAE共同设计和扩展ConvNet
替换U-Net!DiT:基于Transformer的可扩展扩散模型
扩散模型在医学图像上击败GAN
NMS(非极大值抑制)的反击!DETA:基于Transformer的新目标检测器
CCF论文列表(2022拟定)大更新!MICCAI空降B类!PRCV空降C类!ICLR继续陪跑...
DiffusionDet:第一个用于目标检测的扩散模型
65.4 AP刷新COCO目标检测新记录!InternImage:探索具有可变形卷积的大规模视觉基础模型
Sea和北大提出新优化器Adan:深度模型都能用!训练ViT和MAE减少一半计算量!
YOLOv4团队打造YOLOv7!最先进的实时目标检测网络来了!
FAIR提出ConvNeXt:2020 年代的卷积网络
清华提出:最新的计算机视觉注意力机制(Attention)综述!
为何Transformer在计算机视觉中如此受欢迎?
Transformer一脚踹进医学图像分割!看5篇MICCAI 2021有感
回复
使用道具
举报
海千山千
当前离线
积分
4
海千山千
1
主题
4
帖子
4
积分
新手上路
新手上路, 积分 4, 距离下一级还需 46 积分
新手上路, 积分 4, 距离下一级还需 46 积分
积分
4
发消息
发表于 2023-3-4 07:36:19
|
显示全部楼层
这是什么原理
[发呆]
回复
使用道具
举报
奪掵書玍
当前离线
积分
37
奪掵書玍
1
主题
20
帖子
37
积分
新手上路
新手上路, 积分 37, 距离下一级还需 13 积分
新手上路, 积分 37, 距离下一级还需 13 积分
积分
37
发消息
发表于 2025-11-15 01:58:52
|
显示全部楼层
前排顶,很好!
回复
使用道具
举报
此人须珍藏
当前离线
积分
49
此人须珍藏
6
主题
24
帖子
49
积分
新手上路
新手上路, 积分 49, 距离下一级还需 1 积分
新手上路, 积分 49, 距离下一级还需 1 积分
积分
49
发消息
发表于 2025-12-18 15:34:41
|
显示全部楼层
楼下的接上
回复
使用道具
举报
从前那故事
当前离线
积分
29
从前那故事
2
主题
16
帖子
29
积分
新手上路
新手上路, 积分 29, 距离下一级还需 21 积分
新手上路, 积分 29, 距离下一级还需 21 积分
积分
29
发消息
发表于 2025-12-18 21:22:28
|
显示全部楼层
佩服佩服!
回复
使用道具
举报
小龙虾来了
当前离线
积分
31
小龙虾来了
2
主题
20
帖子
31
积分
新手上路
新手上路, 积分 31, 距离下一级还需 19 积分
新手上路, 积分 31, 距离下一级还需 19 积分
积分
31
发消息
发表于 2025-12-21 02:49:03
|
显示全部楼层
支持,赞一个
回复
使用道具
举报
天天超市
当前离线
积分
16
天天超市
1
主题
8
帖子
16
积分
新手上路
新手上路, 积分 16, 距离下一级还需 34 积分
新手上路, 积分 16, 距离下一级还需 34 积分
积分
16
发消息
发表于 2025-12-21 04:41:28
|
显示全部楼层
看帖要回,回帖才健康,在踩踩,楼主辛苦了!
回复
使用道具
举报
驰宇
当前离线
积分
17
驰宇
2
主题
9
帖子
17
积分
新手上路
新手上路, 积分 17, 距离下一级还需 33 积分
新手上路, 积分 17, 距离下一级还需 33 积分
积分
17
发消息
发表于 2026-1-16 09:20:03
|
显示全部楼层
LZ帖子不给力,勉强给回复下吧
回复
使用道具
举报
湖南爱格巨创家居有限公司
当前离线
积分
36
湖南爱格巨创家居有限公司
5
主题
17
帖子
36
积分
新手上路
新手上路, 积分 36, 距离下一级还需 14 积分
新手上路, 积分 36, 距离下一级还需 14 积分
积分
36
发消息
发表于 2026-1-22 10:09:36
|
显示全部楼层
为毛老子总也抢不到沙发?!!
回复
使用道具
举报
的做法
当前离线
积分
16
的做法
0
主题
11
帖子
16
积分
新手上路
新手上路, 积分 16, 距离下一级还需 34 积分
新手上路, 积分 16, 距离下一级还需 34 积分
积分
16
发消息
发表于 2026-2-9 10:04:51
|
显示全部楼层
前排,哇咔咔
回复
使用道具
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
搜狐
腾讯
百度
新浪
京东
快速回复
返回顶部
返回列表



 发表于 2023-3-4 07:35:46
发表于 2023-3-4 07:35:46