|
|
前言:本文主要内容是介绍如何用最简单的办法去采集新浪微博的数据,主要是采集指定微博用户发布的微博以及微博收到的回复等内容,可以通过配置项来调整爬取的微博用户列表以及其他属性。
既然说是最简单的办法,那么我们就得先分析微博爬虫可能选择的几个目标网址,首先肯定是最常见的web网站了
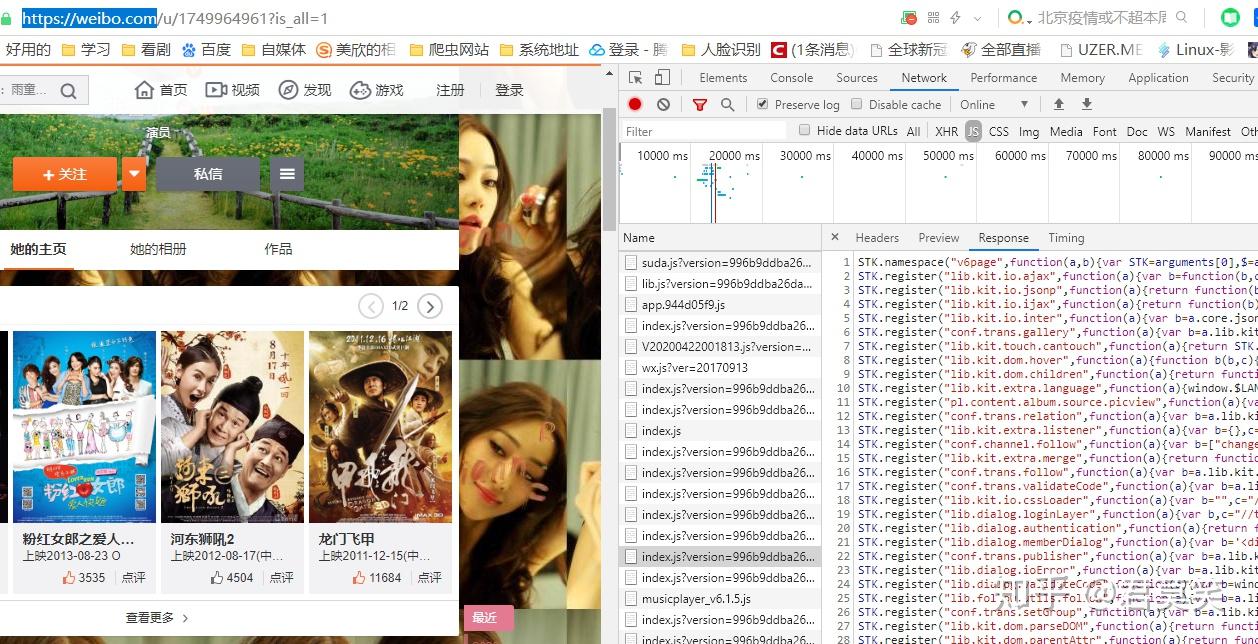
还有就是m站,也就是移动端网页
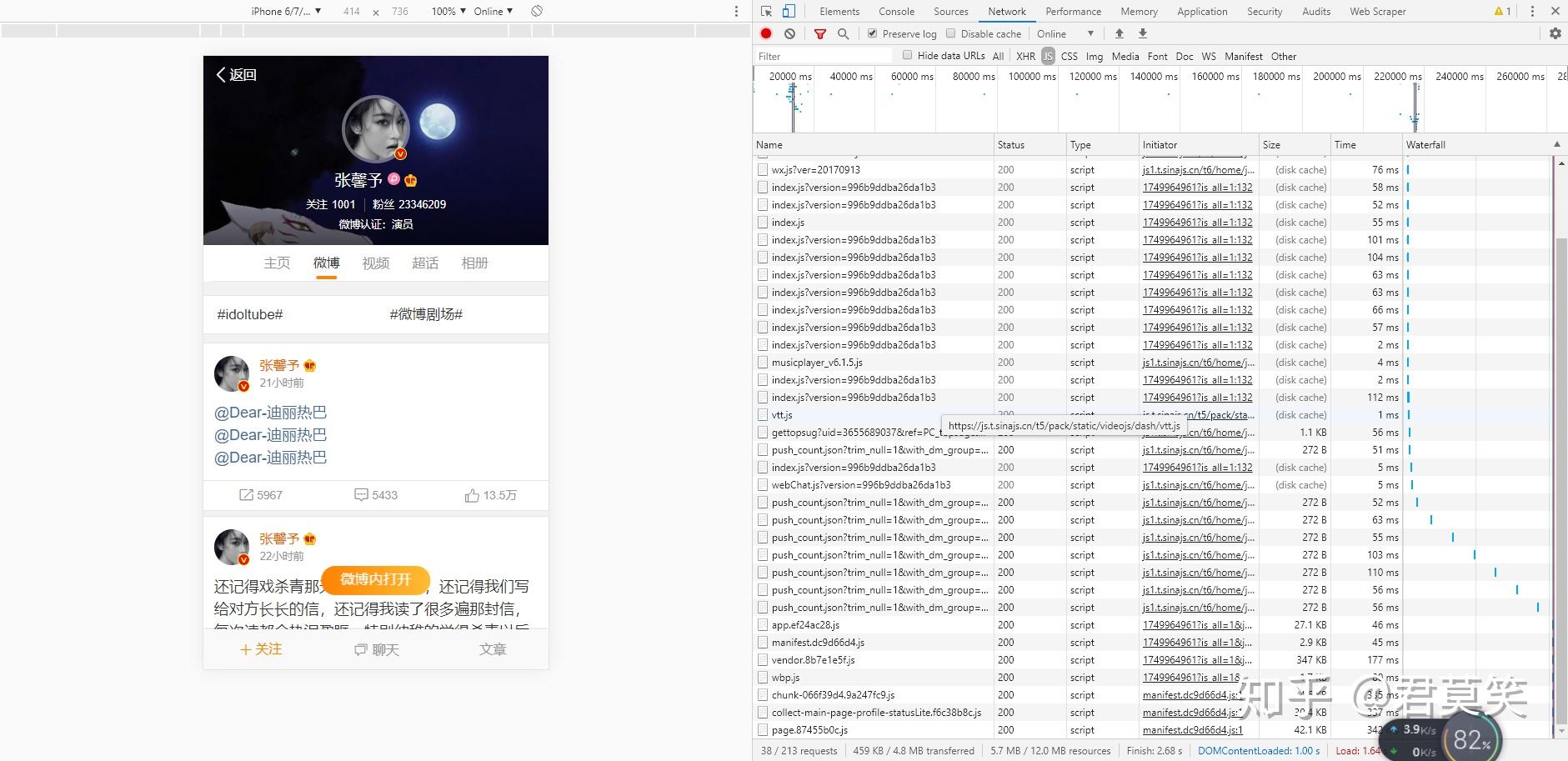
以及一个无法旧版本的访问入口了,首先可以排除web站了,这个是最麻烦的,它的请求是被js加密过,处理起来很麻烦
那我们为何不退而求其次呢,我们观察下这个m站的请求
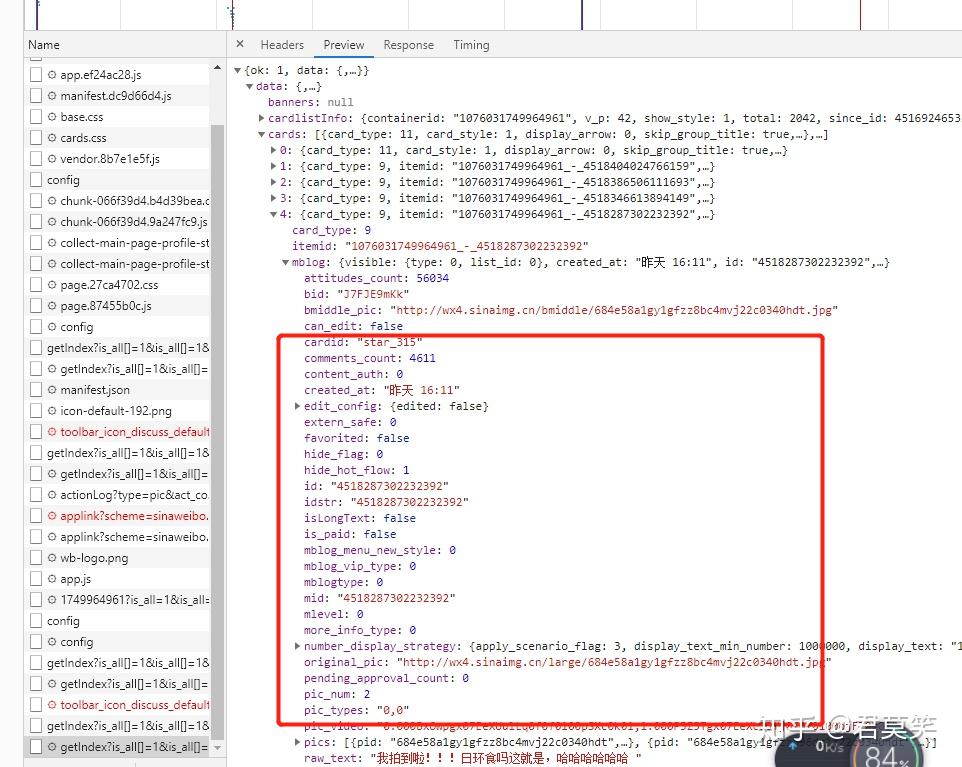
可以发现在某个请求里可以发现我们需要的微博信息,既然这样就好办了,我们就可以着手我们的代码了
首先是获取用户信息,通过用户信息获取用户的微博总数,这样就可以知道总共多少页的数据了,代码如下所示
def get_json(self, params):
"""获取网页中json数据"""
url = 'https://m.weibo.cn/api/container/getIndex?'
r = requests.get(url, params=params, cookies=self.cookie)
return r.json()
def get_page_count(self):
"""获取微博页数"""
try:
weibo_count = self.user['statuses_count']
page_count = int(math.ceil(weibo_count / 10.0))
return page_count
except KeyError:
sys.exit(u'程序出错')
def get_user_info(self):
"""获取用户信息"""
params = {'containerid': '100505' + str(weibo_config['user_id'])}
js = self.get_json(params)
if js['ok']:
info = js['data']['userInfo']
user_info = {}
user_info['id'] = weibo_config['user_id']
user_info['screen_name'] = info.get('screen_name', '')
user_info['gender'] = info.get('gender', '')
user_info['statuses_count'] = info.get('statuses_count', 0)
user_info['followers_count'] = info.get('followers_count', 0)
user_info['follow_count'] = info.get('follow_count', 0)
user_info['description'] = info.get('description', '')
user_info['profile_url'] = info.get('profile_url', '')
user_info['profile_image_url'] = info.get('profile_image_url', '')
user_info['avatar_hd'] = info.get('avatar_hd', '')
user_info['urank'] = info.get('urank', 0)
user_info['mbrank'] = info.get('mbrank', 0)
user_info['verified'] = info.get('verified', False)
user_info['verified_type'] = info.get('verified_type', 0)
user_info['verified_reason'] = info.get('verified_reason', '')
user = self.standardize_info(user_info)
self.user = user分页采集数据
page1 = 0
random_pages = random.randint(1, 5)
self.start_date = datetime.now().strftime('%Y-%m-%d')
for page in tqdm(range(1, page_count + 1), desc='Progress'):
is_end = self.get_one_page(page)
if is_end:
break
if page % 20 == 0: # 每爬20页写入一次文件
self.weibo_to_mysql(wrote_count)
wrote_count = self.got_count
# 通过加入随机等待避免被限制。爬虫速度过快容易被系统限制(一段时间后限
# 制会自动解除),加入随机等待模拟人的操作,可降低被系统限制的风险。默
# 认是每爬取1到5页随机等待6到10秒,如果仍然被限,可适当增加sleep时间
if (page - page1) % random_pages == 0 and page < page_count:
sleep(random.randint(6, 10))
page1 = page
random_pages = random.randint(1, 5)
self.weibo_to_mysql(wrote_count) # 将剩余不足20页的微博写入文件
print(u&#39;微博爬取完成,共爬取%d条微博&#39; % self.got_count)具体采集单页微博代码如下
def get_one_page(self, page):
&#34;&#34;&#34;获取一页的全部微博&#34;&#34;&#34;
try:
js = self.get_weibo_json(page)
if js[&#39;ok&#39;]:
weibos = js[&#39;data&#39;][&#39;cards&#39;]
for w in weibos:
if w[&#39;card_type&#39;] == 9:
wb = self.get_one_weibo(w)
if wb:
if wb[&#39;id&#39;] in self.weibo_id_list:
continue
created_at = datetime.strptime(
wb[&#39;created_at&#39;], &#39;%Y-%m-%d&#39;)
since_date = datetime.strptime(
self.since_date, &#39;%Y-%m-%d&#39;)
if created_at < since_date:
if self.is_pinned_weibo(w):
continue
else:
print(u&#39;{}已获取{}({})的第{}页微博{}&#39;.format(
&#39;-&#39; * 30, self.user[&#39;screen_name&#39;],
self.user[&#39;id&#39;], page, &#39;-&#39; * 30))
return True
if (&#39;retweet&#39; not in wb.keys()):
self.weibo.append(wb)
self.weibo_id_list.append(wb[&#39;id&#39;])
self.got_count += 1
print(u&#39;{}已获取{}({})的第{}页微博{}&#39;.format(&#39;-&#39; * 30,
self.user[&#39;screen_name&#39;],
self.user[&#39;id&#39;], page,
&#39;-&#39; * 30))
except Exception as e:
print(&#34;Error: &#34;, e)
traceback.print_exc()获取具体微博信息的代码
def get_one_weibo(self, info):
&#34;&#34;&#34;获取一条微博的全部信息&#34;&#34;&#34;
try:
weibo_info = info[&#39;mblog&#39;]
weibo_id = weibo_info[&#39;id&#39;]
retweeted_status = weibo_info.get(&#39;retweeted_status&#39;)
is_long = weibo_info.get(&#39;isLongText&#39;)
if retweeted_status: # 转发
retweet_id = retweeted_status.get(&#39;id&#39;)
is_long_retweet = retweeted_status.get(&#39;isLongText&#39;)
if is_long:
weibo = self.get_long_weibo(weibo_id)
if not weibo:
weibo = self.parse_weibo(weibo_info)
else:
weibo = self.parse_weibo(weibo_info)
if is_long_retweet:
retweet = self.get_long_weibo(retweet_id)
if not retweet:
retweet = self.parse_weibo(retweeted_status)
else:
retweet = self.parse_weibo(retweeted_status)
retweet[&#39;created_at&#39;] = self.standardize_date(
retweeted_status[&#39;created_at&#39;])
weibo[&#39;retweet&#39;] = retweet
else: # 原创
if is_long:
weibo = self.get_long_weibo(weibo_id)
if not weibo:
weibo = self.parse_weibo(weibo_info)
else:
weibo = self.parse_weibo(weibo_info)
weibo[&#39;created_at&#39;] = self.standardize_date(
weibo_info[&#39;created_at&#39;])
return weibo
except Exception as e:
print(&#34;Error: &#34;, e)
traceback.print_exc()
def get_long_weibo(self, id):
&#34;&#34;&#34;获取长微博&#34;&#34;&#34;
for i in range(5):
url = &#39;https://m.weibo.cn/detail/%s&#39; % id
html = requests.get(url, cookies=self.cookie).text
html = html[html.find(&#39;&#34;status&#34;:&#39;):]
html = html[:html.rfind(&#39;&#34;hotScheme&#34;&#39;)]
html = html[:html.rfind(&#39;,&#39;)]
html = &#39;{&#39; + html + &#39;}&#39;
js = json.loads(html, strict=False)
weibo_info = js.get(&#39;status&#39;)
if weibo_info:
weibo = self.parse_weibo(weibo_info)
return weibo
sleep(random.randint(6, 10))以上就是核心的微博信息采集代码了,除了微博信息,我们还需要采集微博评论信息,原理是一样的,找到数据来源
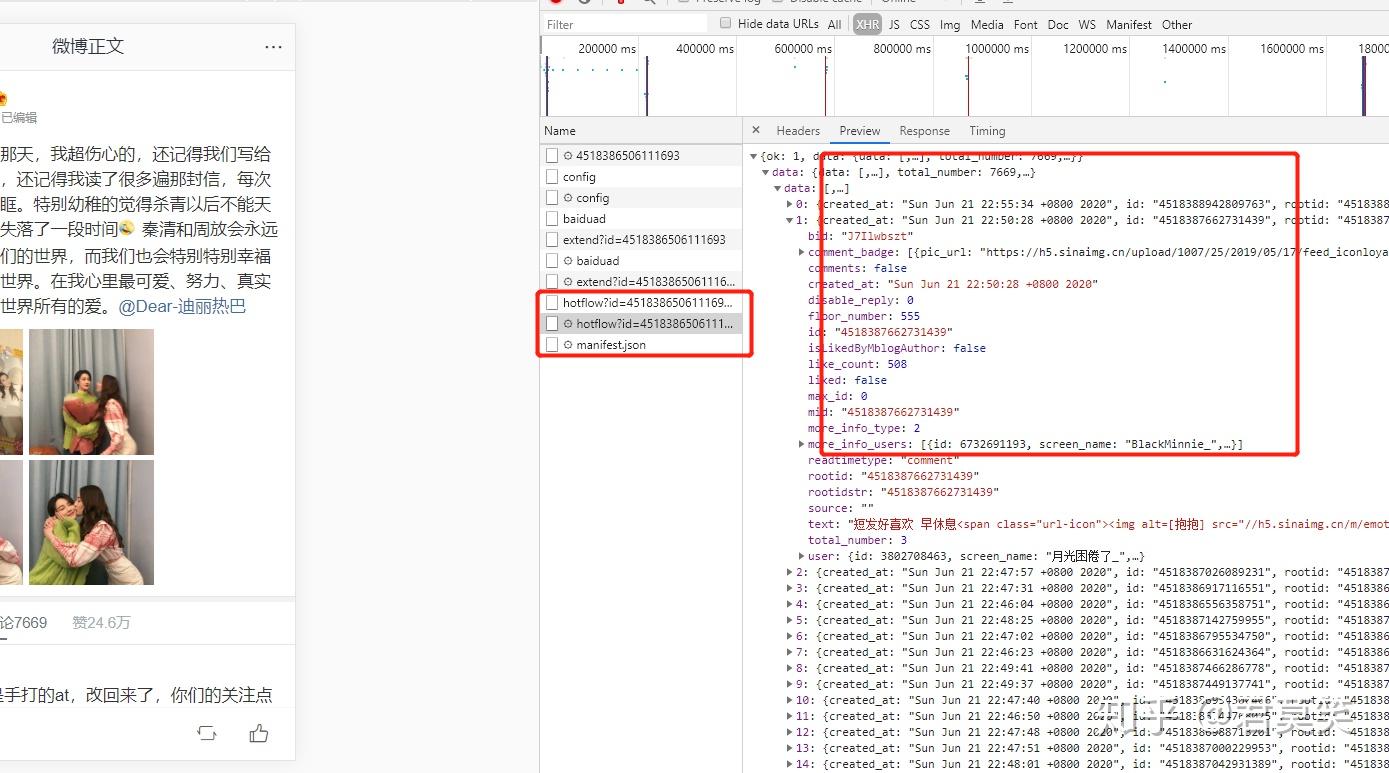
有了微博信息采集的经验,我们很容易就可以找到我们想要的那个接口
具体代码如下
def add_comments_json(self,jsondata):
for data in jsondata:
item = dict()
item[&#39;id&#39;] = data.get(&#39;id&#39;)
item[&#39;mid&#39;] = data.get(&#39;mid&#39;)
item[&#39;like_count&#39;] = data.get(&#34;like_count&#34;)
item[&#39;source&#39;] = data.get(&#34;source&#34;)
item[&#39;floor_number&#39;] = data.get(&#34;floor_number&#34;)
item[&#39;screen_name&#39;] = data.get(&#34;user&#34;).get(&#34;screen_name&#34;)
# 性别
item[&#39;gender&#39;] = data.get(&#34;user&#34;).get(&#34;gender&#34;)
if(item[&#39;gender&#39;] == &#39;m&#39;):
item[&#39;gender&#39;] = &#39;男&#39;
elif(item[&#39;gender&#39;] == &#39;f&#39;):
item[&#39;gender&#39;] = &#39;女&#39;
item[&#39;rootid&#39;] = data.get(&#34;rootid&#34;)
item[&#39;create_time&#39;] = data.get(&#34;created_at&#34;)
import time
item[&#39;create_time&#39;] = time.strptime(item[&#39;create_time&#39;], &#39;%a %b %d %H:%M:%S %z %Y&#39;)
item[&#39;create_time&#39;] = time.strftime(&#39;%Y-%m-%d&#39;,item[&#39;create_time&#39;])
item[&#39;comment&#39;] = data.get(&#34;text&#34;)
item[&#39;comment&#39;] = BeautifulSoup(item[&#39;comment&#39;], &#39;html.parser&#39;).get_text()
item[&#39;comment&#39;] = self.clear_character_chinese(item[&#39;comment&#39;])
print(&#39;当前楼层{},评论{}&#39;.format(item[&#39;floor_number&#39;],item[&#39;comment&#39;]))
# 评论这条评论的信息
comments = data.get(&#34;comments&#34;)
if(comments):
self.add_comments_json(comments)
# print jsondata.dumps(comment, encoding=&#34;UTF-8&#34;, ensure_ascii=False)
self.comments.append(item)
def get_comments_page(self,max_id, id_type,mid):
from get_weibo_cookie import get_cookie
params = {
&#39;max_id&#39;: max_id,
&#39;max_id_type&#39;: id_type
}
try:
url = &#39;https://m.weibo.cn/comments/hotflow?id={id}&amp;mid={mid}&amp;max_id=&#39;
headers = {
&#39;Cookie&#39;: &#39;T_WM=96849642965; __guid=52195957.2500582256236055600.1583058027995.9556; WEIBOCN_FROM=1110006030; SCF=Aimq85D9meHNU4Ip0PFUjYBTDjXFB0VtQr3EKoS8DHQDobRNUO3lDIufAcUg69h4J7BQWqryxQpuU3ReIHHxvQ4.; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5H0p180lDMiCjNvXD_-uOh5JpX5KzhUgL.FoM0S0n0eo-0Sh.2dJLoI0qLxKqL1KMLBK-LxK-LBonLBonLxKMLB.-L12-LxK-LBK-LBoeLxK-L1hnL1hqLxKBLB.2LB-zt; XSRF-TOKEN=ca0a29; SUB=_2A25zWlwFDeRhGeFN7FoS8ivPzzWIHXVQpWRNrDV6PUJbkdANLW_9kW1NQ8CH90H5f8j5r1NA4GNPvu6__ERL-Jat; SUHB=0vJIkXXtLIIaZO; SSOLoginState=1583230037; MLOGIN=1; M_WEIBOCN_PARAMS=oid%3D4474164293517551%26luicode%3D20000174%26lfid%3D102803%26uicode%3D20000174; monitor_count=45&#39;,
&#39;User-Agent&#39;: &#39;Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36&#39;,
&#39;X-Requested-With&#39;: &#39;XMLHttpRequest&#39;
}
r = requests.get(url.format(id=mid,mid=mid), params=params,headers=headers)
print(r.url)
if r.status_code == 200:
return r.json()
except requests.ConnectionError as e:
print(&#39;error&#39;, e.args)
def add_comments(self,jsondata):
datas = jsondata.get(&#39;data&#39;).get(&#39;data&#39;)
for data in datas:
item = dict()
item[&#39;id&#39;] = data.get(&#39;id&#39;)
item[&#39;mid&#39;] = data.get(&#39;mid&#39;)
item[&#39;like_count&#39;] = data.get(&#34;like_count&#34;)
item[&#39;source&#39;] = data.get(&#34;source&#34;)
item[&#39;floor_number&#39;] = data.get(&#34;floor_number&#34;)
item[&#39;screen_name&#39;] = data.get(&#34;user&#34;).get(&#34;screen_name&#34;)
# 性别
item[&#39;gender&#39;] = data.get(&#34;user&#34;).get(&#34;gender&#34;)
if(item[&#39;gender&#39;] == &#39;m&#39;):
item[&#39;gender&#39;] = &#39;男&#39;
elif(item[&#39;gender&#39;] == &#39;f&#39;):
item[&#39;gender&#39;] = &#39;女&#39;
item[&#39;created_at&#39;] = self.standardize_date(
data.get([&#39;created_at&#39;]))
import time
item[&#39;create_time&#39;] = time.strptime(item[&#39;create_time&#39;], &#39;%a %b %d %H:%M:%S %z %Y&#39;)
item[&#39;create_time&#39;] = time.strftime(&#39;%Y-%m-%d&#39;,item[&#39;create_time&#39;])
item[&#39;rootid&#39;] = data.get(&#34;rootid&#34;)
item[&#39;comment&#39;] = data.get(&#34;text&#34;)
item[&#39;comment&#39;] = BeautifulSoup(item[&#39;comment&#39;], &#39;html.parser&#39;).get_text()
item[&#39;comment&#39;] = self.clear_character_chinese(item[&#39;comment&#39;])
print(&#39;当前楼层{},评论{}&#39;.format(item[&#39;floor_number&#39;],item[&#39;comment&#39;]))
# 评论这条评论的信息
comments = data.get(&#34;comments&#34;)
# print jsondata.dumps(comment, encoding=&#34;UTF-8&#34;, ensure_ascii=False)
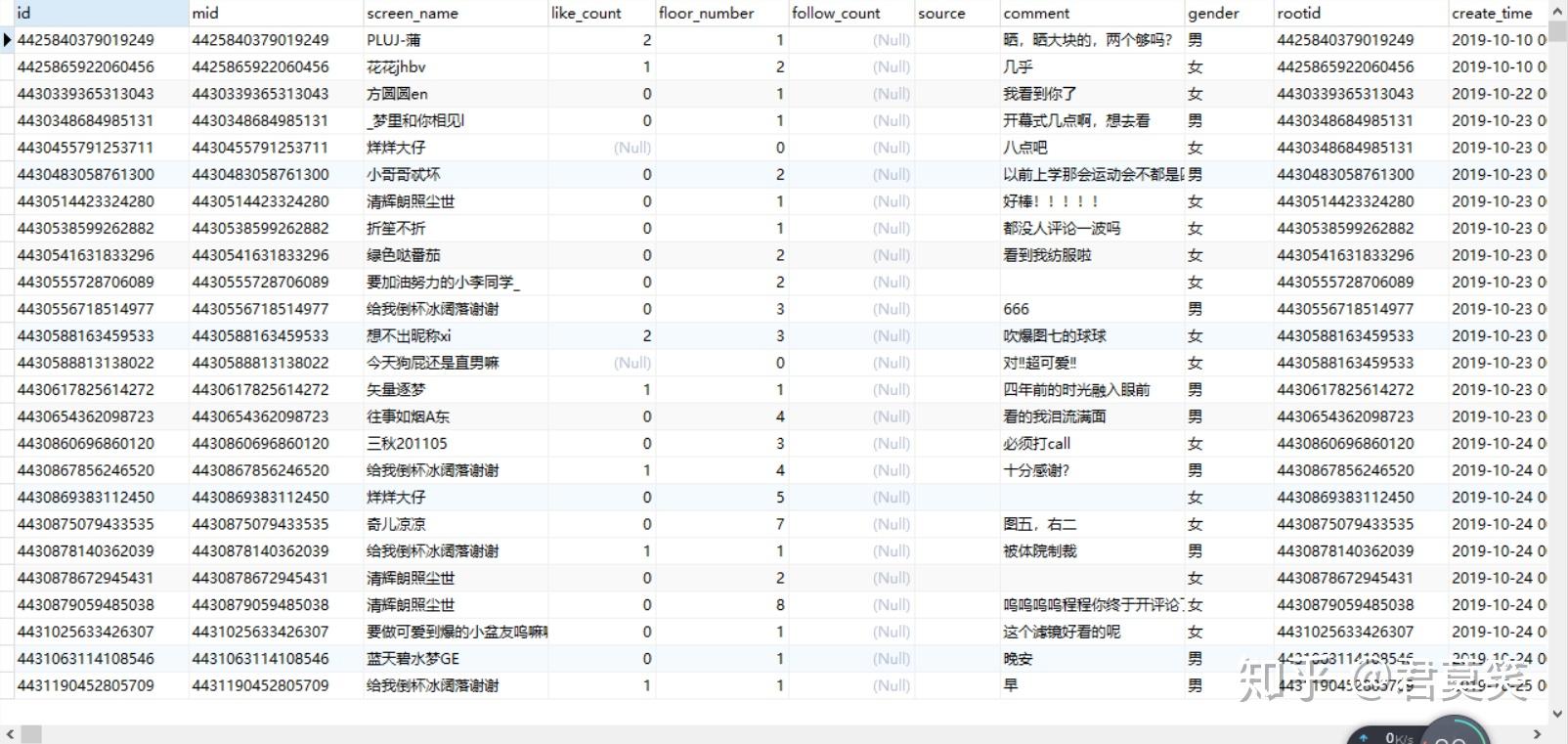
self.comments.append(item)我们可以查看下采集到的数据,如下所示

完整代码可以去我的开源项目中查看或者下载,欢迎star,或者留言与我进行交流。
https://gitee.com/chengrongkai/OpenSpiders
本文收发于https://www.bizhibihui.com/blog/article/44 |
|



 发表于 2023-1-17 15:22:39
发表于 2023-1-17 15:22:39