微信扫一扫 分享朋友圈
4
13
27
新手上路
金磊 Pine 发自 凹非寺 量子位 | 公众号 QbitAI
未来已至。
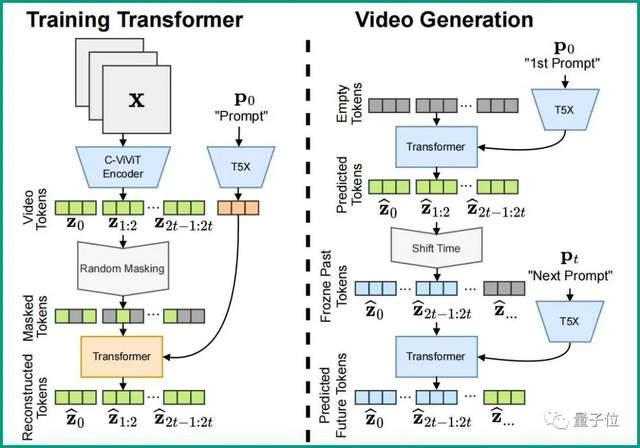
在一座未来感十足的城市里,交通纷繁复杂,这时,一艘外星飞船抵达了城市。 随着镜头的拉近,画面进入到了飞船内部;而后镜头沿着船内长廊继续向前推进,直到看到一名宇航员在蓝色的房间里敲键盘打字。 镜头逐渐移向宇航员的左侧,身后出现蓝色海洋,鱼儿们在水里徜徉;画面快速放大聚焦到一条鱼的身上。 随后镜头快速从海里浮出,直到看到摩天大楼高耸林立的未来城市;镜头再快速拉近到一撞大楼的办公室。 这时,一只狮子突然跳到办公桌上并开始奔跑;镜头先聚焦到狮子的脸上,等再次拉远时,这只狮子已经幻化成西装革履的“兽人”。 最后,镜头从办公室拉出,落日余晖下鸟瞰这座城市。
一只逼真的泰迪熊正在潜水;随后它慢慢浮出水面;走上沙滩;这时镜头拉远,泰迪熊行走在海滩边篝火旁。
在火星上,宇航员走过一个水坑,水里倒映着他的侧影;他在水旁起舞;然后宇航员开始遛狗;最后他和小狗一起看火星上看烟花。
0-1总会很快,1-100还是会很漫长。
AI要多久才能成为新的视频编辑器,或者拿下奥斯卡?
使用道具 举报
2
3
7
18
34
1
26
33
11
21
24
5
25
47
20
44
15
本版积分规则 发表回复 回帖后跳转到最后一页



 发表于 2023-1-17 07:47:40
发表于 2023-1-17 07:47:40