② Presto
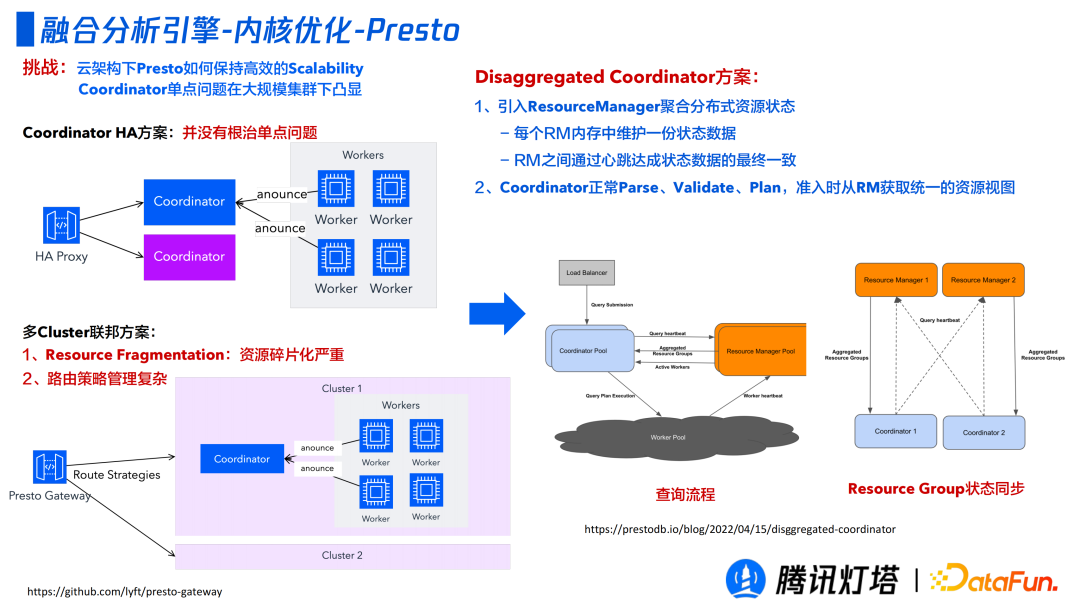
云架构 Presto 在大规模集群下如何保持高效的 Scalabaility Coordinator 单点问题是一个公认的挑战,这部分优化并非我们独创,而是业界的一个 feature。 第一种方案是 Coordinator HA 方案,但其并没有从根源解决问题,一旦 Active 节点失活,过不久 stand by 节点也会挂掉。 第二种方案是多 Cluster 联邦方案,部署多个集群,通过 Presto Gateway 路由不同的集群。但是路由策略管理是一个很大的难点,如果路由策略不当会带来严重的资源碎片化。 第三种方案是 Disaggregated Coordinator 方案,引入了 ResouceManager 聚合分布式资源状态,每个 RM 内存中维护一份状态数据,RM 之间通过心跳达成状态数据的最终一致。Coordinator 可以正常的 Parse、Validate、Plan,准入时 RM 统一获取资源视图,判断是执行还是等待等状态。
③ Kudu
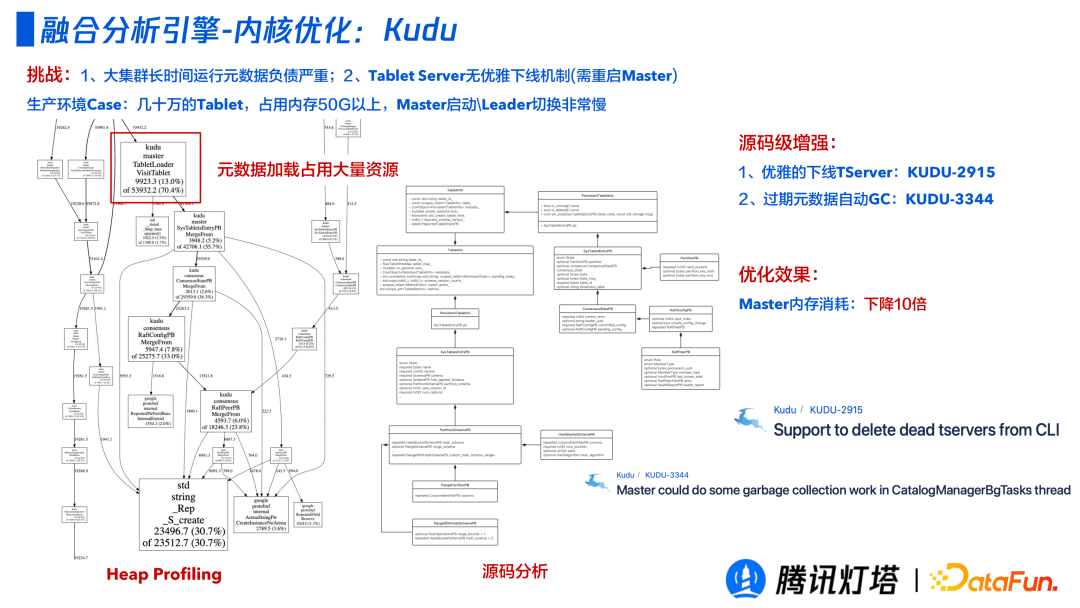
这是一个不常见的问题,在一个运行很久的大集群,有一台机器要裁撤,由于大集群长时间运行元信息负债严重,导致 Tablet Server 无法优雅下线(需要重启 master),耗时可能高达几小时。
在一次实际生产 Case 中,几十万 Tablet,占用内存 50G 以上,Master 启动和Leader 切换都非慢。经排查,集群一直在加载元数据,并发现以前删除的表和数据集群还在维护。通过源码级别的增强,Master 内存消耗降低 10 倍。
② BI Engine
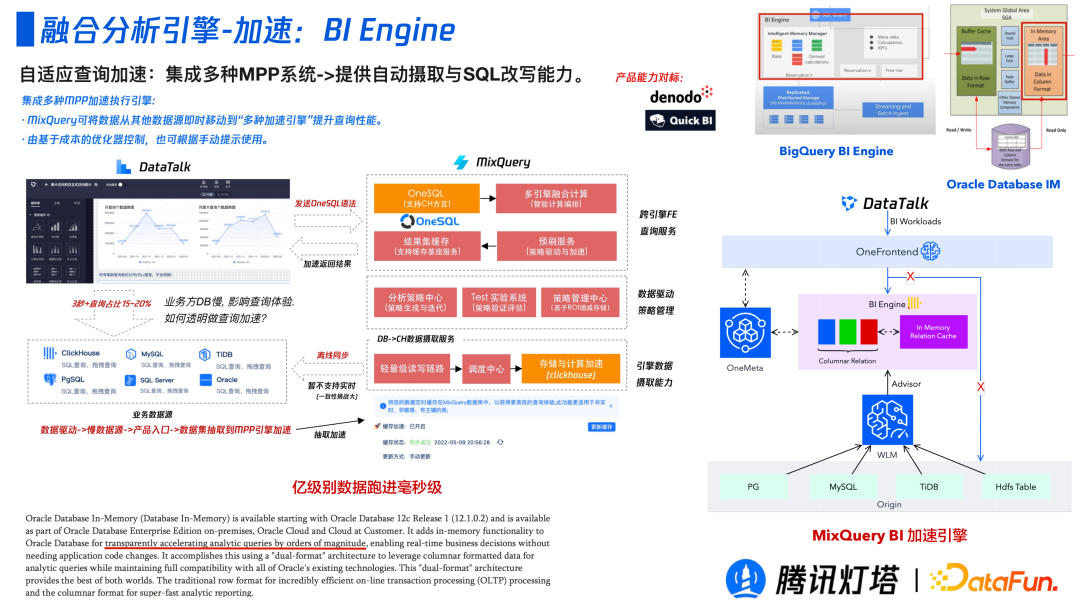
由于 BI 场景不用其他的查询分析场景,BI 场景下的看板对出数的时延要求很高,所以需要 BI 场景进行了特殊的优化。借鉴以 BigQuery 为例,它是有一块单独的内存池,它会根据历史查询判断出热数据并以列式的缓存下来。该引擎除了使用到上述的默认策略,还会添加一个 Clickhouse 的缓存层,基于历史记录判断那些数据是可加速并透明的将可加速的表移动到 Clickhouse 中作为缓存数据。这一整套策略可以让亿级数据运行至毫秒级。
③ 现代的物化视图
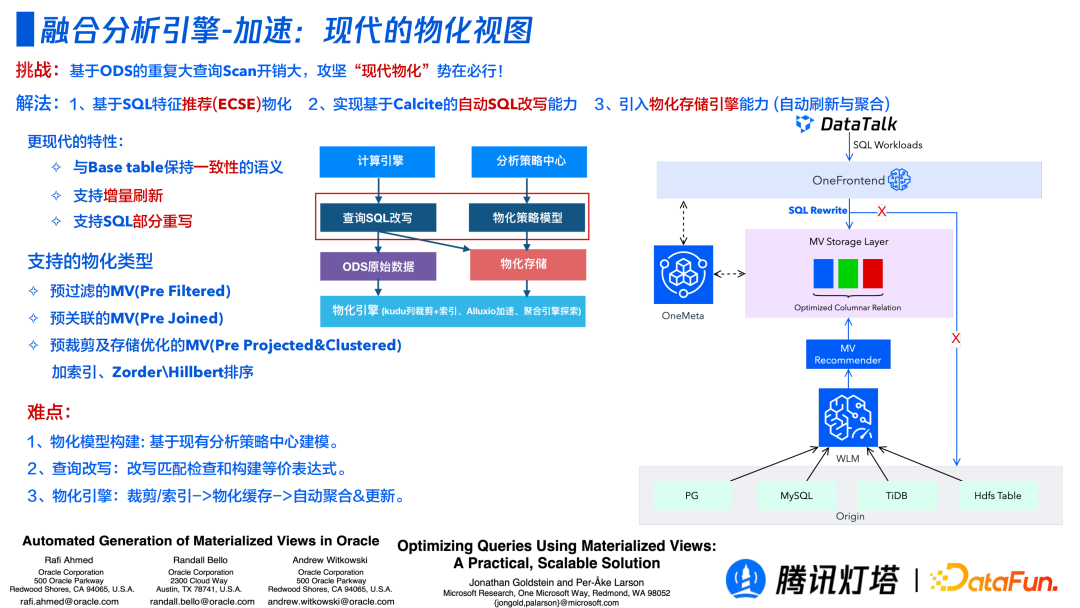
如何更高效利用好物化视图面临着三个问题:如何达到用最少成本达到最高性能;如何低成本维护好物化视图;查询时,在不改变查询语句的前提下如何将查询路由到不同的物化视图? 现代物化视图就是在致力于解决上述三个问题。



 发表于 2023-2-10 15:53:16
发表于 2023-2-10 15:53:16